Decision Tree
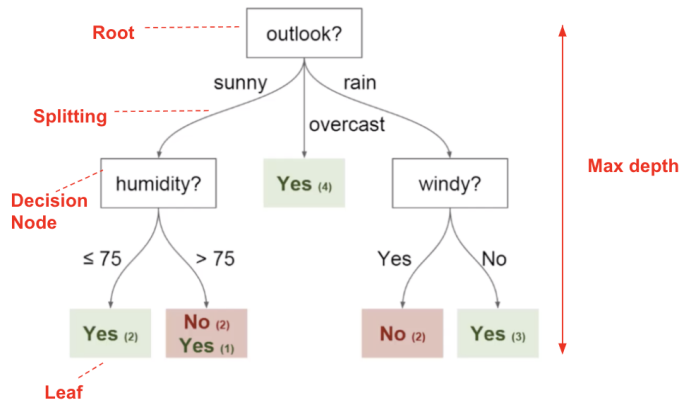
A decision tree can be used to visually and explicitly represent decisions and decision making. As the name goes, it uses a tree-like model of decisions that has influenced a wide area of machine learning, covering both classification and regression.
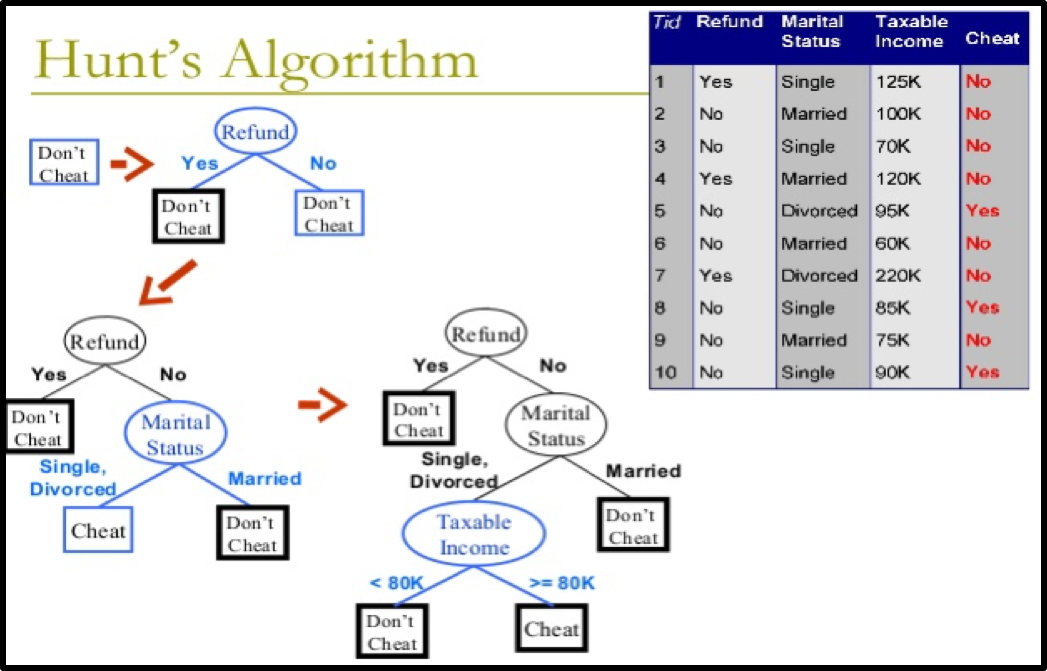
If Dt contains records that belong the same class yt, then t is a leaf node labeled as yt.
If Dt is an empty set, then t is a leaf node labeled by the default class, yd.
If Dt contains records that belong to more than one class, use an attribute test to split the data into smaller subsets.
-
GINI IMPURITY
Gini impurity is a measure of how often a randomly chosen element from the set would be incorrectly labeled if it was randomly labeled according to the distribution of labels in the subset. -
ENTROPY
Entropy is the measure of randomness in the system.

- Generally Data is split into Training data and Testing data for model training.
- Model is trained on Training Data and later on its accuracy is calculated on the basis of Results taken using Testing Dataset.
- While training the model a very common complication occurs that is called OVER-fitting.
- Basically, overfitting refers to a model which has learnt the training data so well, that it fails to work accurately on Validation Set.
- In actual, the model learns the noise and details of training data, hence, it negatively impacts the performance of the model on new (test) data.