diff --git a/.github/workflows/run_chatgpt_examples.yml b/.github/workflows/run_chatgpt_examples.yml
index e269f392baab..f79180d9fa86 100644
--- a/.github/workflows/run_chatgpt_examples.yml
+++ b/.github/workflows/run_chatgpt_examples.yml
@@ -19,7 +19,7 @@ jobs:
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
runs-on: [self-hosted, ubuntu-latest]
container:
- image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
+ image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.5.1-12.4.1
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data --shm-size=10.24gb
timeout-minutes: 180
defaults:
@@ -29,9 +29,18 @@ jobs:
- name: Checkout ColossalAI
uses: actions/checkout@v2
+ - name: Install torch
+ run: |
+ pip uninstall flash-attn
+ pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
+
+ - name: Install flash-attn
+ run: |
+ pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
+
- name: Install Colossal-AI
run: |
- pip install --no-cache-dir -v -e .
+ BUILD_EXT=1 pip install --no-cache-dir -v -e .
- name: Install ChatGPT
env:
@@ -39,14 +48,13 @@ jobs:
CXXFLAGS: "-O1"
MAX_JOBS: 4
run: |
- pip install flash-attn --no-build-isolation
cd applications/ColossalChat
- pip install --no-cache-dir -v .
+ pip install --no-cache-dir -v -e .
pip install --no-cache-dir -r examples/requirements.txt
- - name: Install Transformers
- run: |
- pip install --no-cache-dir transformers==4.36.2
+ # - name: Install Transformers
+ # run: |
+ # pip install --no-cache-dir transformers==4.36.2
- name: Execute Examples
run: |
diff --git a/applications/ColossalChat/coati/distributed/README.md b/applications/ColossalChat/coati/distributed/README.md
index 21647a8cc896..4f3fe94f6b31 100644
--- a/applications/ColossalChat/coati/distributed/README.md
+++ b/applications/ColossalChat/coati/distributed/README.md
@@ -14,6 +14,7 @@ This repository implements a distributed Reinforcement Learning (RL) training fr
* **Rollout and Policy Decoupling**: Efficient generation and consumption of data through parallel inferencer-trainer architecture.
* **Evaluation Integration**: Easily plug in task-specific eval datasets.
* **Checkpoints and Logging**: Configurable intervals and directories.
+* **[New]**: Zero Bubble training framework that supports GRPO and DAPO. [(read more)](./zero_bubble/README.md)
---
diff --git a/applications/ColossalChat/coati/distributed/comm.py b/applications/ColossalChat/coati/distributed/comm.py
index 3824303f55bd..21e6c7d90c79 100644
--- a/applications/ColossalChat/coati/distributed/comm.py
+++ b/applications/ColossalChat/coati/distributed/comm.py
@@ -1,5 +1,7 @@
+import copy
from typing import Any, Dict
+import ray
import ray.util.collective as cc
import torch
import torch.distributed.distributed_c10d as c10d
@@ -32,9 +34,17 @@ def ray_broadcast_object(obj: Any, src: int = 0, device=None, group_name: str =
def ray_broadcast_tensor_dict(
- tensor_dict: Dict[str, torch.Tensor], src: int = 0, device=None, group_name: str = "default"
+ tensor_dict: Dict[str, torch.Tensor],
+ src: int = 0,
+ device=None,
+ group_name: str = "default",
+ backend: str = "nccl",
+ offload_to_cpu: bool = False,
+ pin_memory: bool = False,
) -> Dict[str, torch.Tensor]:
rank = cc.get_rank(group_name)
+ if tensor_dict is None:
+ tensor_dict = {}
if rank == src:
metadata = []
for k, v in tensor_dict.items():
@@ -42,16 +52,103 @@ def ray_broadcast_tensor_dict(
else:
metadata = None
metadata = ray_broadcast_object(metadata, src, device, group_name)
- if rank != src:
- out_dict = {}
for k, shape, dtype in metadata:
if rank == src:
- tensor = tensor_dict[k]
+ if offload_to_cpu:
+ tensor = tensor_dict[k].to(device)
+ else:
+ tensor = tensor_dict[k]
else:
- tensor = torch.empty(shape, dtype=dtype, device=device)
+ tensor = tensor_dict.get(k, torch.zeros(shape, dtype=dtype, device=device, pin_memory=pin_memory))
+ if backend == "gloo" and dtype == torch.bfloat16:
+ # Gloo does not support bfloat16, convert to float16
+ tensor = tensor.view(torch.float16)
cc.broadcast(tensor, src, group_name)
+ if backend == "gloo" and dtype == torch.bfloat16:
+ # Convert back to bfloat16 if it was converted to float16
+ tensor = tensor.view(torch.bfloat16)
if rank != src:
- out_dict[k] = tensor
- if rank == src:
- out_dict = tensor_dict
- return out_dict
+ if offload_to_cpu:
+ tensor_dict[k] = tensor.cpu()
+ else:
+ tensor_dict[k] = tensor
+ return tensor_dict
+
+
+@ray.remote
+class SharedVariableActor:
+ def __init__(self, number_of_readers: int = 0, buffer_size_limit: int = 1000):
+ self.data_queue = []
+ self.data_uid = 0
+ self.number_of_readers = number_of_readers
+ self.queue_size = 0
+ self.signals = {}
+ self.process_locks = {}
+ self.signal_procs_meet_count = {}
+ self.buffer_size_limit = buffer_size_limit
+
+ def pickup_rollout_task(self, num_tasks: int):
+ """
+ use queue size to control whether producers should generating new rollouts or wait
+ for consumer to consumer more data. if queue size is less than threshold,
+ it means consumer is consuming data fast enough, so producers can generate new rollouts.
+ if queue size is greater than threshold, it means consumer is consuming data slowly,
+ so producers should wait for consumer to consume more data.
+
+ Any free producer can pick up the task to generate rollout then increase the queued_data_size
+ to prevent other producer to pick up the task redundantly, Note it is not the real
+ queue length as data may still be generating
+ """
+ ret = False
+ if self.queue_size < (self.buffer_size_limit / max(0.1, self.signals.get("sample_utilization", 1.0))):
+ ret = True
+ self.queue_size += num_tasks
+ return ret
+
+ def append_data(self, data):
+ self.data_queue.append([self.data_uid, data, 0]) # [data_uid, data, access_count]
+ self.data_uid += 1
+ return True
+
+ def get_data(self, data_uid: int):
+ # for multi-process data reading
+ if not self.data_queue:
+ # no data in the queue, return None
+ return None
+ to_pop_index = None
+ ret = None
+ for i, (uid, data, access_count) in enumerate(self.data_queue):
+ if uid == data_uid:
+ # found the data with the given uid
+ self.data_queue[i][2] += 1
+ ret = copy.deepcopy(data)
+ if self.data_queue[i][2] == self.number_of_readers:
+ to_pop_index = i
+ break
+ if to_pop_index is not None:
+ # remove the data from the queue if it has been accessed by all readers
+ self.data_queue.pop(to_pop_index)
+ self.queue_size -= data["input_ids"].size(0)
+ return ret
+
+ def acquire_process_lock(self, key: str):
+ # atomic lock for process
+ if key not in self.process_locks:
+ self.process_locks[key] = 1 # locked
+ return 0
+ if self.process_locks[key] == 0:
+ self.process_locks[key] = 1 # lock the process
+ return 0
+ else:
+ return 1
+
+ def release_process_lock(self, key: str):
+ # atomic unlock for process
+ assert self.process_locks.get(key, 0) == 1, f"Releasing a process lock {key} that is not locked."
+ self.process_locks[key] = 0
+
+ def set_signal(self, key: str, signal: str):
+ self.signals[key] = signal
+
+ def get_signal(self):
+ return self.signals
diff --git a/applications/ColossalChat/coati/distributed/inference_backend.py b/applications/ColossalChat/coati/distributed/inference_backend.py
index 34827e4e2cf9..331f8d7b6a01 100644
--- a/applications/ColossalChat/coati/distributed/inference_backend.py
+++ b/applications/ColossalChat/coati/distributed/inference_backend.py
@@ -59,6 +59,7 @@ def __init__(
generate_config: Dict[str, Any],
tokenizer: PreTrainedTokenizer,
num_generations: int = 8,
+ tokenizer_config: Dict[str, Any] = None,
):
model_config = update_by_default(model_config, self.DEFAULT_MODEL_CONFIG)
model_config.update(self.FORCE_MODEL_CONFIG)
@@ -132,6 +133,7 @@ def __init__(
generate_config: Dict[str, Any],
tokenizer: PreTrainedTokenizer,
num_generations: int = 8,
+ tokenizer_config: Dict[str, Any] = None,
):
if sgl is None:
raise ImportError("sglang is not installed")
@@ -196,12 +198,14 @@ def __init__(
generate_config: Dict[str, Any],
tokenizer: PreTrainedTokenizer,
num_generations: int = 8,
+ tokenizer_config: Dict[str, Any] = None,
):
if LLM is None:
raise ImportError("vllm is not installed")
model_config = update_by_default(model_config, self.DEFAULT_MODEL_CONFIG)
path = model_config.pop("path")
- self.llm = LLM(model=path, **model_config)
+ tokenizer_path = tokenizer_config.get("path", None) if tokenizer_config is not None else None
+ self.llm = LLM(model=path, tokenizer=tokenizer_path, **model_config)
generate_config = generate_config.copy()
generate_config.update(self.FORCE_GENERATE_CONFIG)
generate_config.update({"n": num_generations})
diff --git a/applications/ColossalChat/coati/distributed/launch_zero_bubble.py b/applications/ColossalChat/coati/distributed/launch_zero_bubble.py
new file mode 100644
index 000000000000..de5b6135360b
--- /dev/null
+++ b/applications/ColossalChat/coati/distributed/launch_zero_bubble.py
@@ -0,0 +1,305 @@
+import copy
+import os
+import uuid
+from typing import Any, Dict, Optional
+
+import ray
+
+from .comm import SharedVariableActor
+from .zero_bubble.distributor import Distributor
+from .zero_bubble.grpo_consumer import GRPOConsumer
+from .zero_bubble.producer import SimpleProducer
+
+ALGO_MAP = {"GRPO": GRPOConsumer, "DAPO": GRPOConsumer}
+
+
+def get_jsonl_size_fast(path: str) -> int:
+ with open(path) as f:
+ lines = f.readlines()
+ lines = [line for line in lines if line.strip()]
+ return len(lines)
+
+
+def get_dp_size_fast(n_procs: int, plugin_config: Dict[str, Any]) -> int:
+ tp_size = plugin_config.get("tp_size", 1)
+ pp_size = plugin_config.get("pp_size", 1)
+ ep_size = plugin_config.get("ep_size", 1)
+ sp_size = plugin_config.get("sp_size", 1)
+ return n_procs // (tp_size * pp_size * ep_size * sp_size)
+
+
+def launch_distributed(
+ num_producers: int,
+ num_proc_per_producer: int,
+ num_consumer_procs: int,
+ num_episodes: int,
+ inference_batch_size: int,
+ inference_microbatch_size: int,
+ train_batch_size: int,
+ train_minibatch_size: int,
+ train_dataset_config: Dict[str, Any],
+ inference_model_config: Dict[str, Any],
+ generate_config: Dict[str, Any],
+ train_model_config: Dict[str, Any],
+ grpo_config: Dict[str, Any],
+ plugin_config: Dict[str, Any],
+ tokenizer_config: Optional[Dict[str, Any]] = None,
+ inference_backend: str = "transformers",
+ num_generations: int = 8,
+ master_addr: str = "localhost",
+ master_port: int = 29500,
+ core_algo: str = "GRPO",
+ project_name: Optional[str] = None,
+ save_interval: int = 100,
+ save_dir: str = "./model",
+ eval_dataset_config: Optional[Dict[str, Any]] = None,
+ eval_interval: int = 100,
+ eval_save_dir: Optional[str] = None,
+ eval_generation_config: Optional[Dict[str, Any]] = None,
+ log_rollout_interval: int = 20,
+ rollout_save_dir: str = "./rollout",
+ enable_profiling: bool = False,
+ data_actor_buffer_size_limit: int = 0,
+):
+ if core_algo not in ALGO_MAP:
+ raise NotImplementedError(f"{core_algo} is not supported yet.")
+ else:
+ core_consumer = ALGO_MAP.get(core_algo, GRPOConsumer)
+
+ train_dp_size = get_dp_size_fast(num_consumer_procs, plugin_config)
+ assert (inference_batch_size * num_producers) % (train_batch_size * train_dp_size) == 0
+ if data_actor_buffer_size_limit <= 0:
+ # use 2 times the train_minibatch_size as the default buffer size limit
+ data_actor_buffer_size_limit = train_minibatch_size * train_dp_size * 2
+
+ dataset_path = train_dataset_config["path"]
+ train_dataset_size = get_jsonl_size_fast(dataset_path)
+ global_inference_batch_size = inference_batch_size * num_producers
+ train_dataset_size = (train_dataset_size // global_inference_batch_size) * global_inference_batch_size
+
+ run_name = f"{inference_backend}_bs_{train_batch_size * train_dp_size}_temp_{generate_config['temperature']:.01f}_top_p_{generate_config['top_p']:.02f}"
+ wandb_group_name = str(uuid.uuid4())
+ rollout_log_file = os.path.join(
+ rollout_save_dir,
+ f"{project_name.replace(' ','_')}_run_{wandb_group_name}.jsonl",
+ )
+
+ # Attention: Ray use complex schedualing method that consider various factors including load-balancing.
+ # when requesting resources, it is not guaranteed that the resource comes from a node with lower node it
+ # this go against the design principle of our implementation, and we need to manually force the schedualing,
+ # allocating the producer to nodes with lower node id and the consumer to the resouces from nodes with higher
+ # node id. See the reference here: https://docs.ray.io/en/latest/ray-core/scheduling/index.html#nodeaffinityschedulingstrategy
+ nodes = ray.nodes()
+
+ # every producer is associated with a data worker, data worker is responsible for moving data from the producer to all consumer
+ shared_sync_data_actor = SharedVariableActor.remote(num_consumer_procs, data_actor_buffer_size_limit)
+ # all producer and the consumer 0 share the same model actor, model actor only provide signal for model synchronization
+ shared_signal_actor = SharedVariableActor.remote()
+
+ node_info = {
+ node["NodeID"]: {
+ "num_gpus": node["Resources"].get("GPU", 0),
+ "address": node["NodeManagerAddress"],
+ } # Default to 0 if no GPUs are available
+ for node in nodes
+ }
+ gpu_to_node_id = []
+ gpu_to_ip_address = []
+ for node_id in node_info:
+ for idx in range(int(node_info[node_id]["num_gpus"])):
+ gpu_to_node_id.append(node_id)
+ gpu_to_ip_address.append(node_info[node_id]["address"])
+ print(node_info)
+
+ producer_procs = []
+ for i in range(num_producers):
+ node_id = gpu_to_node_id[0]
+ producer_ip_address = gpu_to_ip_address[0]
+ for _ in range(num_proc_per_producer):
+ gpu_to_node_id.pop(0)
+ gpu_to_ip_address.pop(0)
+ print(f"Schedual Producer P[{i}] which requires {num_proc_per_producer} GPUs on node {producer_ip_address}")
+ producer = SimpleProducer.options(num_gpus=num_proc_per_producer, num_cpus=4).remote(
+ shared_sync_data_actor=shared_sync_data_actor,
+ shared_signal_actor=shared_signal_actor,
+ producer_idx=i,
+ num_producers=num_producers,
+ num_consumer_procs=num_consumer_procs,
+ num_episodes=num_episodes,
+ batch_size=inference_batch_size,
+ train_dataset_config=train_dataset_config,
+ model_config=inference_model_config,
+ generate_config=generate_config,
+ tokenizer_config=copy.deepcopy(tokenizer_config),
+ microbatch_size=inference_microbatch_size,
+ backend=inference_backend,
+ num_generations=num_generations,
+ consumer_plugin_config=plugin_config,
+ eval_dataset_config=eval_dataset_config,
+ eval_interval=eval_interval,
+ grpo_config=grpo_config,
+ eval_save_dir=eval_save_dir,
+ eval_generation_config=eval_generation_config,
+ project_name=project_name,
+ run_name=run_name,
+ wandb_group_name=wandb_group_name,
+ log_rollout_interval=log_rollout_interval,
+ rollout_log_file=rollout_log_file,
+ enable_profiling=enable_profiling,
+ )
+ producer_procs.append(producer)
+ # ray.get([p.setup.remote() for p in producer_procs])
+ generate_config_consumer = copy.deepcopy(generate_config)
+ generate_config_consumer.update(
+ dict(
+ backend=inference_backend,
+ )
+ )
+ consumer_master_ip_address = gpu_to_ip_address[0]
+ print(f"Use {consumer_master_ip_address} as master address for torch DDP.")
+ consumer_procs = []
+ for i in range(num_consumer_procs):
+ node_id = gpu_to_node_id[0]
+ consumer_ip_address = gpu_to_ip_address[0]
+ gpu_to_node_id.pop(0)
+ gpu_to_ip_address.pop(0)
+ print(f"Schedual Consumer T[{i}] which requires 1 GPUs on node {consumer_ip_address}")
+ consumer = core_consumer.options(num_gpus=1, num_cpus=4).remote(
+ shared_sync_data_actor=shared_sync_data_actor,
+ shared_signal_actor=shared_signal_actor,
+ num_producers=num_producers,
+ num_episodes=num_episodes,
+ rank=i,
+ world_size=num_consumer_procs,
+ master_addr=consumer_master_ip_address,
+ master_port=master_port,
+ train_dataset_size=train_dataset_size,
+ batch_size=train_batch_size,
+ model_config=train_model_config,
+ plugin_config=plugin_config,
+ minibatch_size=train_minibatch_size,
+ tokenizer_config=copy.deepcopy(tokenizer_config),
+ generate_config=generate_config_consumer,
+ grpo_config=grpo_config,
+ num_generations=num_generations,
+ save_interval=save_interval,
+ save_dir=save_dir,
+ project_name=project_name,
+ run_name=run_name,
+ wandb_group_name=wandb_group_name,
+ enable_profiling=enable_profiling,
+ )
+ consumer_procs.append(consumer)
+
+ distributor_procs = []
+ for i in range(num_producers):
+ distributor_procs.append(
+ Distributor.options(num_cpus=2).remote(
+ i,
+ plugin_config.get("pp_size", 1),
+ num_producers,
+ shared_signal_actor,
+ enable_profiling=enable_profiling,
+ )
+ )
+ print("=================== All processes are created, starting setup torch DDP ===================", flush=True)
+ ray.get([p.setup.remote() for p in consumer_procs])
+ print(
+ "=================== All processes are setup, starting initialize communication groups ===================",
+ flush=True,
+ )
+ remote_refs = []
+ # Initialize consumer communication group
+ for i, p in enumerate(consumer_procs):
+ remote_refs.append(p.init_collective_group.remote(num_consumer_procs, i, "gloo", f"consumer_pg"))
+ ray.get(remote_refs)
+ remote_refs = []
+ # Initialize producer communication group
+ for i, p in enumerate(producer_procs):
+ remote_refs.append(p.init_collective_group.remote(num_producers, i, "nccl", f"producer_pg"))
+ ray.get(remote_refs)
+ remote_refs = []
+ # Initialize distributor communication group
+ for i, p in enumerate(distributor_procs):
+ remote_refs.append(p.init_collective_group.remote(num_producers, i, "gloo", f"distributor_pg"))
+ ray.get(remote_refs)
+ remote_refs = []
+ # Initialize sync model communication group between consumer and sync model actor
+ # As per tested, gloo do not support nested initialization, so we need to initialize all participants in the same group in the same ray.get call.
+ consumer_pp = plugin_config.get("pp_size", 1)
+ for i, p in enumerate(consumer_procs):
+ consumer_ddp_config = ray.get(p.get_ddp_config.remote())
+ if consumer_pp > 1:
+ if consumer_ddp_config["tp_rank"] == 0 and consumer_ddp_config["dp_rank"] == 0:
+ pp_rank = consumer_ddp_config["pp_rank"]
+ remote_refs.append(
+ p.init_collective_group.remote(
+ num_producers + 1,
+ 0,
+ backend="gloo",
+ group_name=f"sync_model_consumer_pp_{pp_rank}",
+ gloo_timeout=3000000,
+ )
+ )
+ for distributor_id, p_distributor in enumerate(distributor_procs):
+ remote_refs.append(
+ p_distributor.init_collective_group.remote(
+ num_producers + 1,
+ 1 + distributor_id,
+ backend="gloo",
+ group_name=f"sync_model_consumer_pp_{pp_rank}",
+ gloo_timeout=3000000,
+ )
+ )
+ ray.get(remote_refs)
+ remote_refs = []
+ else:
+ if i == 0:
+ remote_refs.append(
+ p.init_collective_group.remote(
+ num_producers + 1, 0, backend="gloo", group_name=f"sync_model_consumer", gloo_timeout=3000000
+ )
+ )
+ for distributor_id, p_distributor in enumerate(distributor_procs):
+ remote_refs.append(
+ p_distributor.init_collective_group.remote(
+ num_producers + 1,
+ 1 + distributor_id,
+ backend="gloo",
+ group_name=f"sync_model_consumer",
+ gloo_timeout=3000000,
+ )
+ )
+ ray.get(remote_refs)
+ remote_refs = []
+ # Initialize sync model communication group between producer and sync model actor
+ for i, p in enumerate(producer_procs):
+ if consumer_pp > 1:
+ for pp_rank in range(consumer_pp):
+ remote_refs.append(
+ p.init_collective_group.remote(
+ 2, 0, backend="gloo", group_name=f"sync_model_producer_{i}_pp_{pp_rank}", gloo_timeout=3000000
+ )
+ )
+ remote_refs.append(
+ distributor_procs[i].init_collective_group.remote(
+ 2, 1, backend="gloo", group_name=f"sync_model_producer_{i}_pp_{pp_rank}", gloo_timeout=3000000
+ )
+ )
+ ray.get(remote_refs)
+ remote_refs = []
+ else:
+ remote_refs.append(
+ p.init_collective_group.remote(
+ 2, 0, backend="gloo", group_name=f"sync_model_producer_{i}", gloo_timeout=3000000
+ )
+ )
+ remote_refs.append(
+ distributor_procs[i].init_collective_group.remote(
+ 2, 1, backend="gloo", group_name=f"sync_model_producer_{i}", gloo_timeout=3000000
+ )
+ )
+ ray.get(remote_refs)
+ remote_refs = []
+ print("=================== All processes are set up, starting loop ===================", flush=True)
+ ray.get([p.loop.remote() for p in (producer_procs + consumer_procs + distributor_procs)])
diff --git a/applications/ColossalChat/coati/distributed/loss.py b/applications/ColossalChat/coati/distributed/loss.py
index ab38f987f65a..7fcfdba31f4d 100644
--- a/applications/ColossalChat/coati/distributed/loss.py
+++ b/applications/ColossalChat/coati/distributed/loss.py
@@ -37,9 +37,9 @@ def forward(
total_effective_tokens_in_batch: torch.Tensor = None,
) -> torch.Tensor:
if action_mask is None:
- ratio = (log_probs - log_probs.detach()).exp()
+ ratio = (log_probs - old_log_probs.detach()).exp()
else:
- ratio = ((log_probs - log_probs.detach()) * action_mask).exp()
+ ratio = ((log_probs - old_log_probs.detach()) * action_mask).exp()
surr1 = ratio * advantages
surr2 = ratio.clamp(1 - self.clip_eps_low, 1 + self.clip_eps_high) * advantages
diff --git a/applications/ColossalChat/coati/distributed/zero_bubble/README.md b/applications/ColossalChat/coati/distributed/zero_bubble/README.md
new file mode 100644
index 000000000000..15f0345f4128
--- /dev/null
+++ b/applications/ColossalChat/coati/distributed/zero_bubble/README.md
@@ -0,0 +1,65 @@
+# Zero Bubble Distributed RL Framework for Language Model Fine-Tuning
+
+This folder contains code for the Zero Bubble distributed RL framework. It currently supports **GRPO** and **DAPO**. See the [main README](../README.md) for general installation instructions and usage.
+
+**Note:** This project is under active development — expect changes.
+
+## 🛠 Installation
+
+1. Follow the general installation guide in the [main README](../README.md).
+2. Install [pygloo](https://github.com/ray-project/pygloo). Build pygloo for Ray from source following the instructions in its repository README.
+
+## Design idea
+
+We aim to reduce the *“bubble”* — the idle time that occurs between rollouts and training steps (illustrated in Fig. 1).
+
+
+
+ 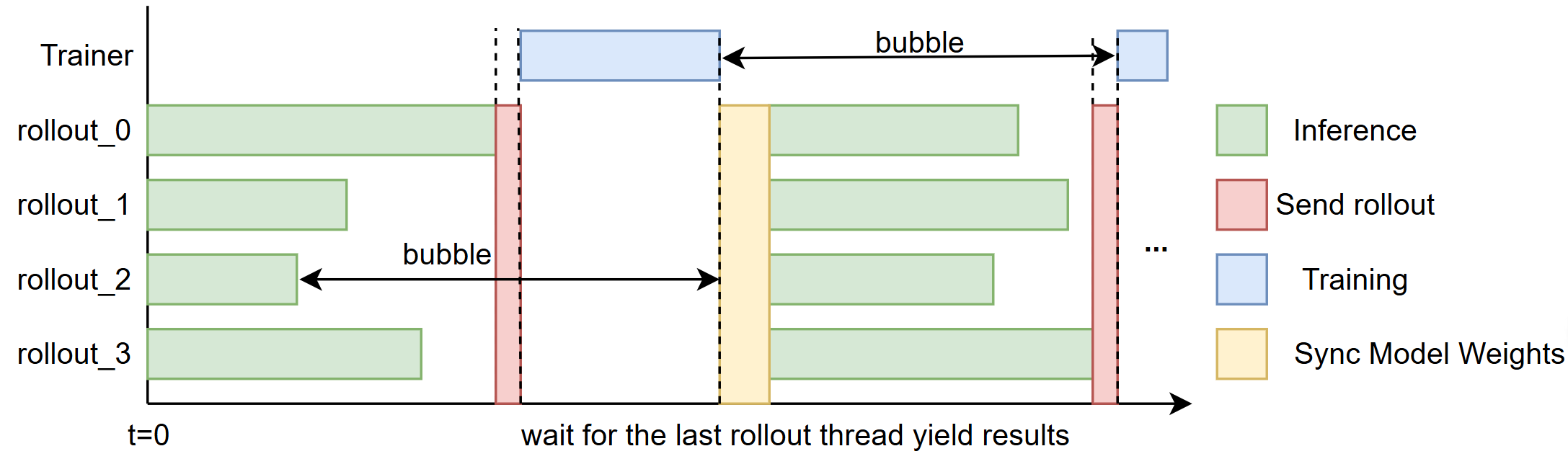 +
+
+
+
+ 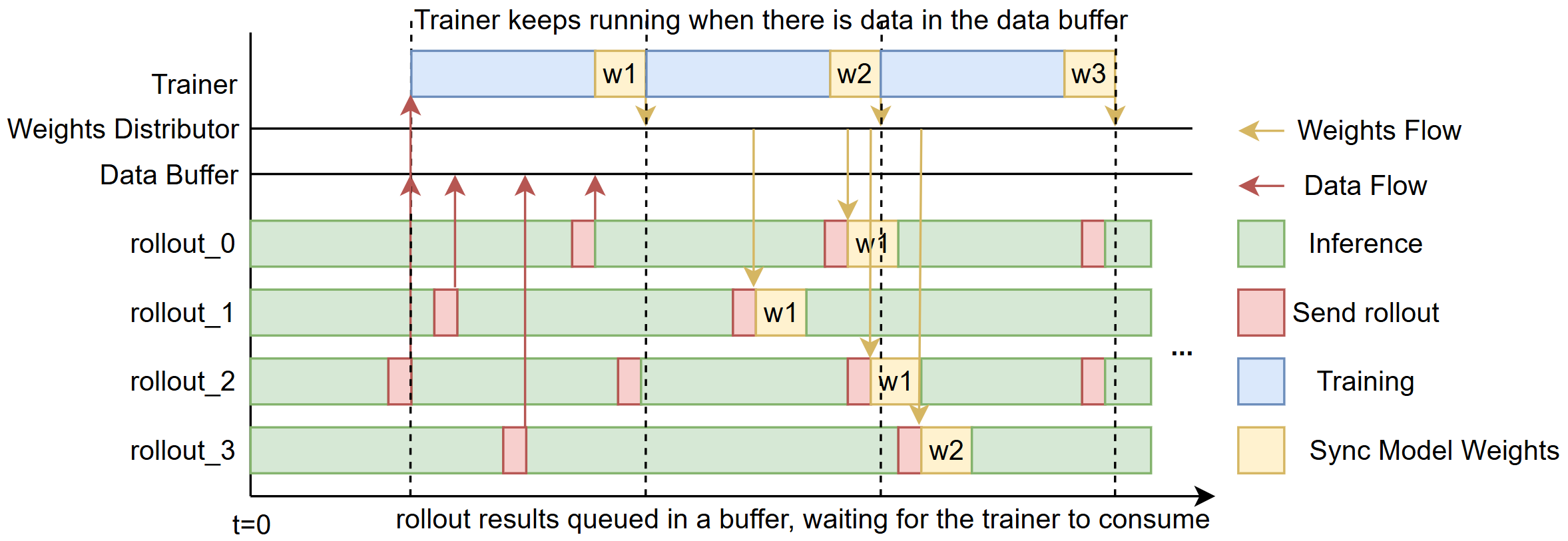 +
+
+
+
+ 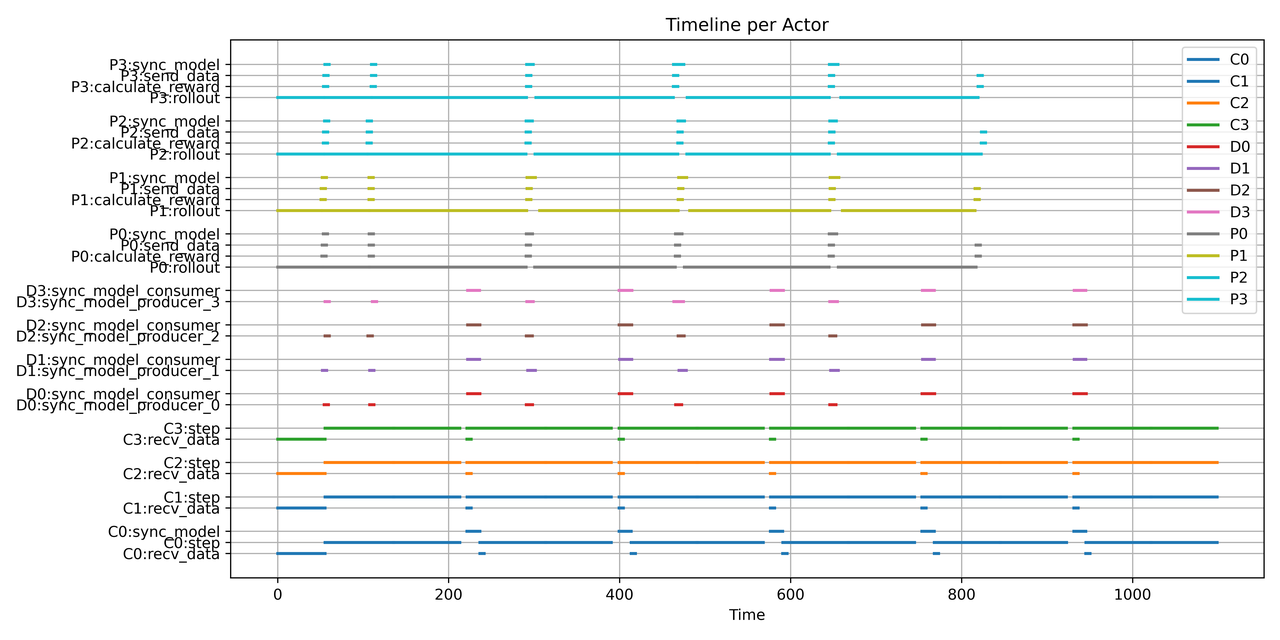 +
+
+