|
1 | | -# Extractive Question Answering |
| 1 | +--- |
| 2 | +title: "AutoTrain Extractive Question Answering - Train QA Models Easily" |
| 3 | +description: "Learn how to train extractive question answering models using AutoTrain. Simple guide for both local and cloud training with popular models like BERT." |
| 4 | +--- |
2 | 5 |
|
3 | | -Extractive Question Answering is a task in which a model is trained to extract the answer to a question from a given context. |
4 | | -The model is trained to predict the start and end positions of the answer span within the context. |
5 | | -This task is commonly used in question-answering systems to extract relevant information from a large corpus of text. |
| 6 | +# Extractive Question Answering with AutoTrain |
6 | 7 |
|
| 8 | +Extractive Question Answering (QA) enables AI models to find and extract precise answers from text passages. This guide shows you how to train custom QA models using AutoTrain, supporting popular architectures like BERT, RoBERTa, and DeBERTa. |
7 | 9 |
|
8 | | -## Preparing your data |
| 10 | +## What is Extractive Question Answering? |
9 | 11 |
|
10 | | -To train an Extractive Question Answering model, you need a dataset that contains the following columns: |
| 12 | +Extractive QA models learn to: |
| 13 | +- Locate exact answer spans within longer text passages |
| 14 | +- Understand questions and match them to relevant context |
| 15 | +- Extract precise answers rather than generating them |
| 16 | +- Handle both simple and complex queries about the text |
11 | 17 |
|
12 | | -- `text`: The context or passage from which the answer is to be extracted. |
13 | | -- `question`: The question for which the answer is to be extracted. |
14 | | -- `answer`: The start position of the answer span in the context. |
| 18 | +## Preparing your Data |
15 | 19 |
|
16 | | -Here is an example of how your dataset should look: |
| 20 | +Your dataset needs these essential columns: |
| 21 | +- `text`: The passage containing potential answers (also called context) |
| 22 | +- `question`: The query you want to answer |
| 23 | +- `answer`: Answer span information including text and position |
17 | 24 |
|
| 25 | +Here is an example of how your dataset should look: |
18 | 26 |
|
19 | 27 | ``` |
20 | 28 | {"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?","answers":{"text":["Saint Bernadette Soubirous"],"answer_start":[515]}} |
21 | 29 | {"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"What is in front of the Notre Dame Main Building?","answers":{"text":["a copper statue of Christ"],"answer_start":[188]}} |
22 | 30 | {"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"The Basilica of the Sacred heart at Notre Dame is beside to which structure?","answers":{"text":["the Main Building"],"answer_start":[279]}} |
23 | 31 | ``` |
24 | 32 |
|
25 | | - |
26 | 33 | Note: the preferred format for question answering is JSONL, if you want to use CSV, the `answer` column should be stringified JSON with the keys `text` and `answer_start`. |
27 | 34 |
|
28 | 35 | Example dataset from Hugging Face Hub: [lhoestq/squad](https://huggingface.co/datasets/lhoestq/squad) |
29 | 36 |
|
30 | | - |
31 | 37 | P.S. You can use both squad and squad v2 data format with correct column mappings. |
32 | 38 |
|
33 | | -## Training Locally |
| 39 | +## Training Options |
| 40 | + |
| 41 | +### Local Training |
| 42 | +Train models on your own hardware with full control over the process. |
34 | 43 |
|
35 | 44 | To train an Extractive QA model locally, you need a config file: |
36 | 45 |
|
@@ -75,12 +84,14 @@ $ autotrain --config config.yaml |
75 | 84 |
|
76 | 85 | Here, we are training a BERT model on the SQuAD dataset using the Extractive QA task. The model is trained for 3 epochs with a batch size of 4 and a learning rate of 2e-5. The training process is logged using TensorBoard. The model is trained locally and pushed to the Hugging Face Hub after training. |
77 | 86 |
|
78 | | -## Training on the Hugging Face Spaces |
| 87 | +### Cloud Training on Hugging Face |
| 88 | +Train models using Hugging Face's cloud infrastructure for better scalability. |
79 | 89 |
|
80 | 90 | 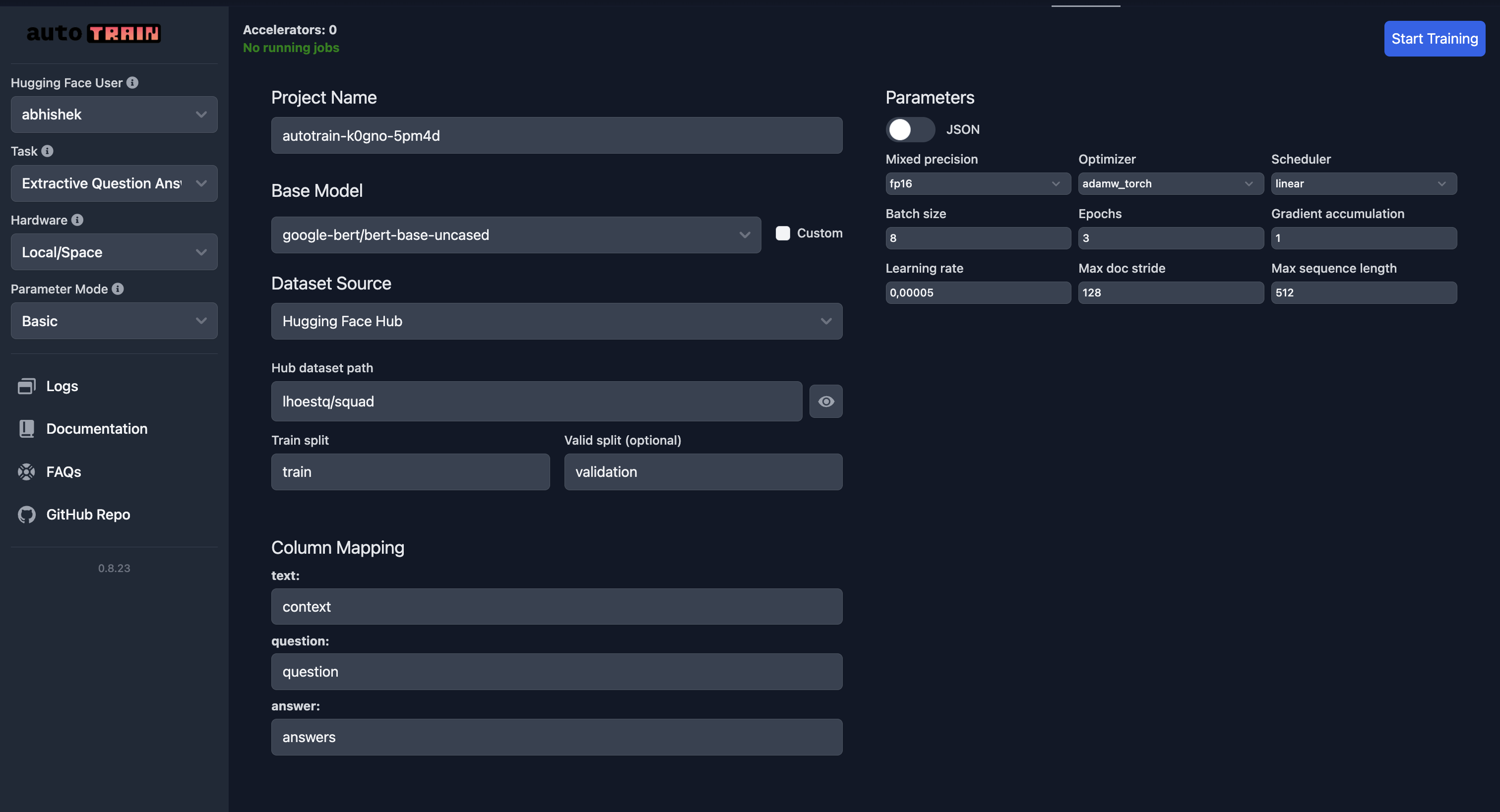 |
81 | 91 |
|
82 | 92 | As always, pay special attention to column mapping. |
83 | 93 |
|
84 | | -## Parameters |
| 94 | + |
| 95 | +## Parameter Reference |
85 | 96 |
|
86 | 97 | [[autodoc]] trainers.extractive_question_answering.params.ExtractiveQuestionAnsweringParams |
0 commit comments