使用Query Builder - Knex.js在数据库表字段和GraphQL Schema定义的字段之间相互转换 #87
Description
# 使用Query Builder - Knex.js在数据库表字段和GraphQL Schema定义的字段之间相互转换
问题
数据库表字段的命名规范为:<表名单数>_<字段名称>,小写,下划线分割单词,ERD如下:
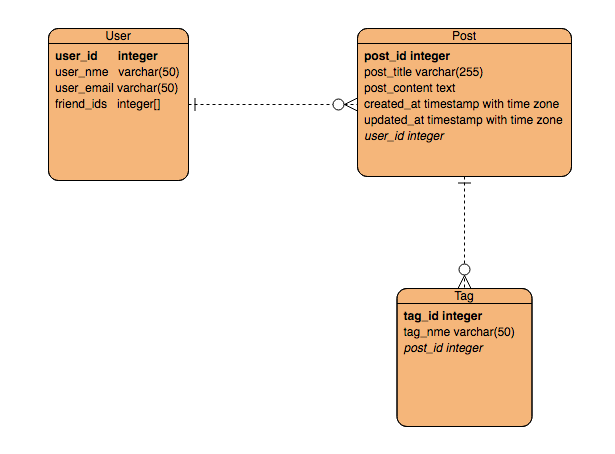
GraphQL定义的Schema字段的命名规范为:<表名单数><字段名称>,驼峰命名,GraphQL Schema可视化模型如下:
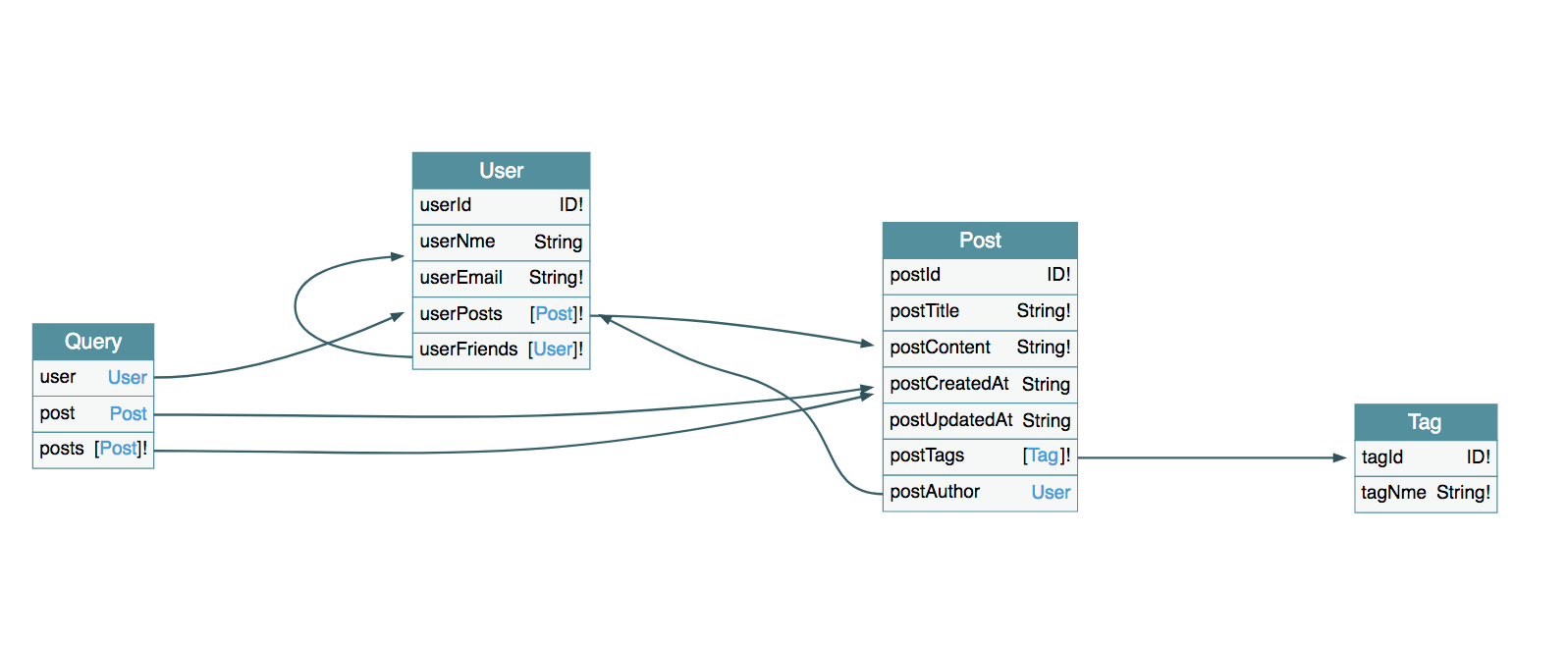
使用Knex.js作为SQL查询构建工具(Query Builder),如何以最小的代价,最简单的方式实现上述数据库表字段到GraphQL Schema字段的转换?
解决方案
Knex.js提供了两个API,分别是postProcessResponse和wrapIdentifier,准确说是钩子函数(hook),用过mongoose的同学应该不会陌生,mongoose中的middleware就是hook:
Middleware (also called pre and post hooks)
简单说就是可以在一个SQL查询执行之前和之后执行预先定义好的hook,我们可以在hook中进行字段的转换,校验等等。
postProcessResponse方法会在每次SQL查询执行之后执行,wrapIdentifier方法在SQL查询执行之前进行标识符(identifier)的转换。在Knex.js Query Builder中出现的数据库Schema名,表名,列名,别名都属于identifier。例如,下述Query Builder:
knex('table').withSchema('foo').select('table.field as otherName').where('id', 1)
wrapIdentifier方法将转换以下标识符:'table', 'foo', 'table', field, 'otherName'和'id'
这两个hooks就是用来进行字段转换的地方,此外,还需要一个转换器(converter),用来在下划线命名和驼峰命名之间进行转换,转换器我使用humps,示意图如下:
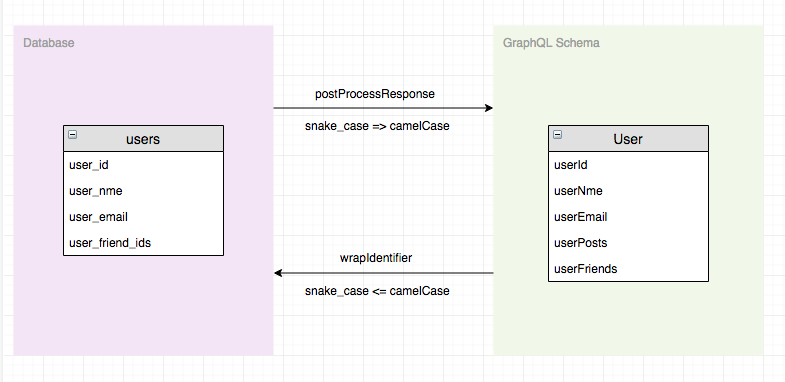
接下来我们开始分析代码,GraphQL Schema定义如下:
import { gql } from 'apollo-server';
const typeDefs = gql`
type User {
userId: ID!
userNme: String
userEmail: String!
userPosts: [Post]!
userFriends: [User]!
}
type Post {
postId: ID!
postTitle: String!
postContent: String!
postCreatedAt: String
postUpdatedAt: String
postTags: [Tag]!
postAuthor: User
}
input PostInput {
postTitle: String!
postContent: String!
postTags: [TagInput]
postAuthorId: ID!
}
input TagInput {
tagNme: String!
}
type Tag {
tagId: ID!
tagNme: String!
}
type CommonResponse {
code: Int!
message: String!
}
type Query {
user(id: ID!): User
post(id: ID!): Post
posts(ids: [ID!]): [Post]!
}
type Mutation {
post(postInput: PostInput!): CommonResponse
}
`;上述Schema分别定义了User, Post, Tag, CommonResponse类型(Object Type),PostInput和TagInput输入类型(Input Type),以及Query,Mutation类型,接着实现各个类型及其字段的resolver,标量类型(Scalar Type),例如ID, String, Int, Boolean会默认解析,一般我们不去写Scalar Type的resolver,有时候还是有需要去写Scalar Type的resolver的场景,举个简单例子引申:
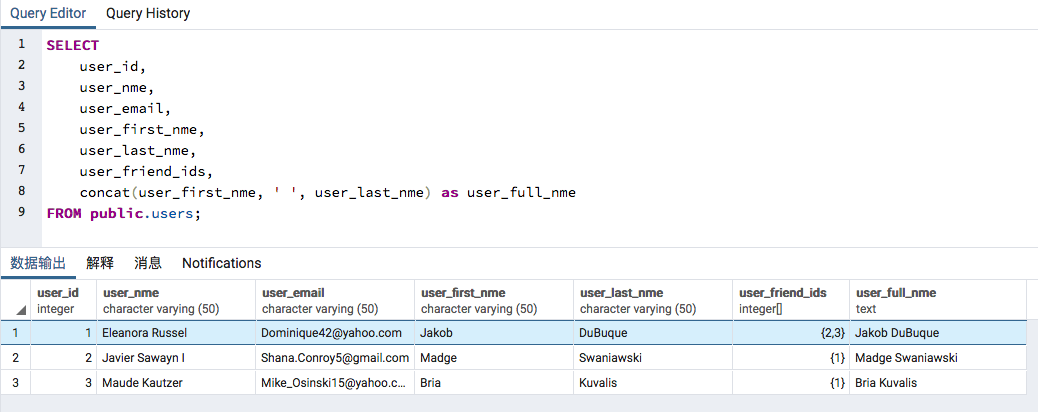
数据库users表数据行如下:

users表,有两个字段,user_first_nme和user_last_nme,好了,现在有个需求是得到user_full_nme这个计算字段,或者叫衍生字段,有两种做法:
- 数据库层面,使用数据库提供的字符串函数
concat和as别名得到user_full_nme,如下:
- GraphQL Resolver层面,其实也就是在应用程序代码层面,通过应用程序代码完成衍生字段的计算。
给User Type的Schema定义中添加userFullNme字段,如下:
type User {
userId: ID!
userNme: String
userEmail: String!
userFullNme: String!
userPosts: [Post]!
userFriends: [User]!
}可以看到,userFullNme是Scalar Type(标量类型),但是现在我们要自己去写resolver来解析这个字段,添加userFullNme字段的resolver,如下:
User: {
userPosts: (user, _, { PostLoader }: IAppContext) => {
return PostLoader.userPosts.load(user.userId);
},
userFriends: (user, _, { UserLoader }: IAppContext) => {
return UserLoader.userFriends.loadMany(user.userFriendIds);
},
userFullNme: (user, _) => {
return user.userFirstNme + ' ' + user.userLastNme;
},
},在userFullNme字段的resolver中,我们使用数据库users表中的存在的字段userFirstNme和userLastNme来计算出userFullNme这个衍生字段。测试一下,结果如下:
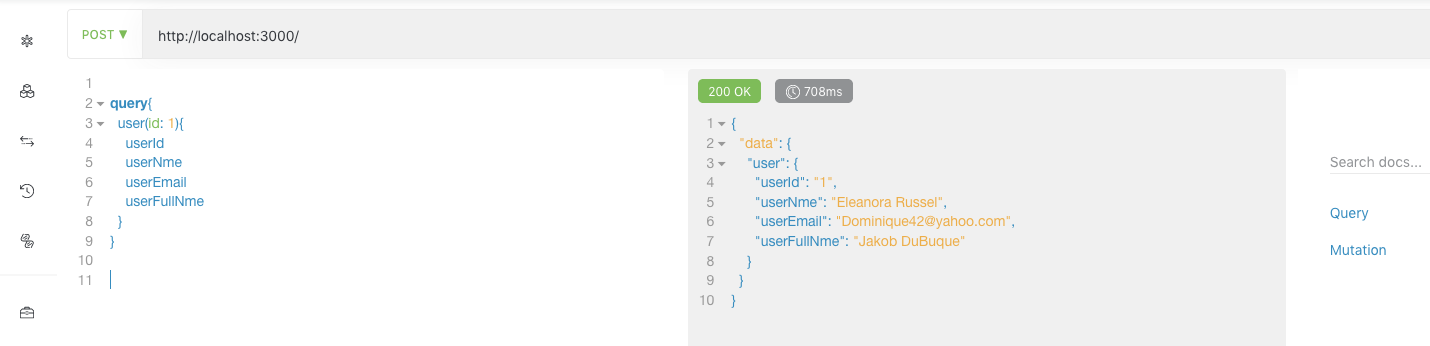
客户端查询userFullNme字段,正确得到了该字段的值。
有同学会问,计算衍生字段也不是必须去使用GraphQL的这种方法呀,数据库层面就可以呀。考虑计算衍生字段这样一种变体,衍生字段可能并不简单的是字符串拼接这种通过数据库提供的内置字符串函数就可以完成的,如果有:
- 业务逻辑
- 依赖外部服务
数据库层面无能为力,这里只做引申,说明在一些场景下,尽管GraphQL Schema定义的字段是Scalar Type,但是需要我们手动编写resolver去解析。
言归正传,对于User Type中的userPosts和userFriends字段,以及Query和Mutation类型,需要我们自己去实现这些字段的resolver,白话讲,就是需要去实现这些类型中各个字段要返回什么数据,是应用程序自己的逻辑,GraphQL并不知道userPosts要返回什么数据。
完整的resolver实现如下:
const resolvers: IResolvers = {
User: {
userPosts: (user, _, { PostLoader }: IAppContext) => {
return PostLoader.userPosts.load(user.userId);
},
userFriends: (user, _, { UserLoader }: IAppContext) => {
return UserLoader.userFriends.loadMany(user.userFriendIds);
},
},
Post: {
postAuthor: (post, _, { PostLoader }: IAppContext) => {
return PostLoader.postAuthor.load(post.postId);
},
postTags: (post, _, { PostLoader }: IAppContext) => {
return PostLoader.postTags.load(post.postId);
},
},
Query: {
user: (_, { id }, { knex }) => {
const sql = `select * from users where user_id = ?;`;
return knex
.raw(sql, [id])
.get('rows')
.get(0);
},
posts: (_, { ids }: { ids?: ID[] }, { knex }: IAppContext) => {
const query = knex('posts').select();
if (ids) {
query.whereIn('post_id', ids);
}
return query;
},
post: (_, { id }, { knex }: IAppContext) => {
return knex('posts')
.where({ post_id: id })
.first();
},
},
Mutation: {
post: (_, { postInput }: { postInput: IPostInput }, { knex }: IAppContext) => {
const commonResponse = { code: 0, message: '' };
return knex
.transaction((trx: Transaction) => {
const post = {
postTitle: postInput.postTitle,
postContent: postInput.postContent,
userId: postInput.postAuthorId,
};
knex('posts')
.transacting(trx)
.insert(post)
.returning(['post_id'])
.then(([postInserted]) => {
if (postInput.postTags) {
const tags = postInput.postTags.map((postTag) => {
return { tagNme: postTag.tagNme, postId: postInserted.postId };
});
return knex('tags')
.transacting(trx)
.insert(tags);
}
return Promise.resolve(postInserted);
})
.then(trx.commit)
.catch(trx.rollback);
})
.then(() => {
commonResponse.message = 'create post success';
return commonResponse;
})
.catch((error) => {
console.error(error);
commonResponse.code = 1;
commonResponse.message = 'create post error';
return commonResponse;
});
},
},
};这里为了保持示例简单,并没有采用分层架构,直接在resolver中写了SQL Query去数据库查询数据。GraphQL Query用来根据入参进行数据查询,Mutation.post, 完成创建post和tag的数据库事务。
好了,启动这个GraphQL Service程序:
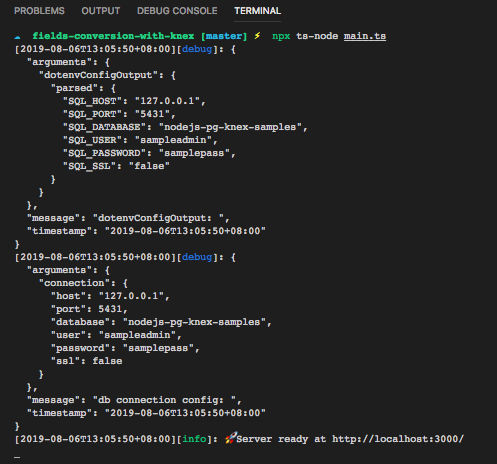
检查打印的环境变量,数据库连接配置,服务器启动正常。接下来使用客户端构造GraphQL Query:
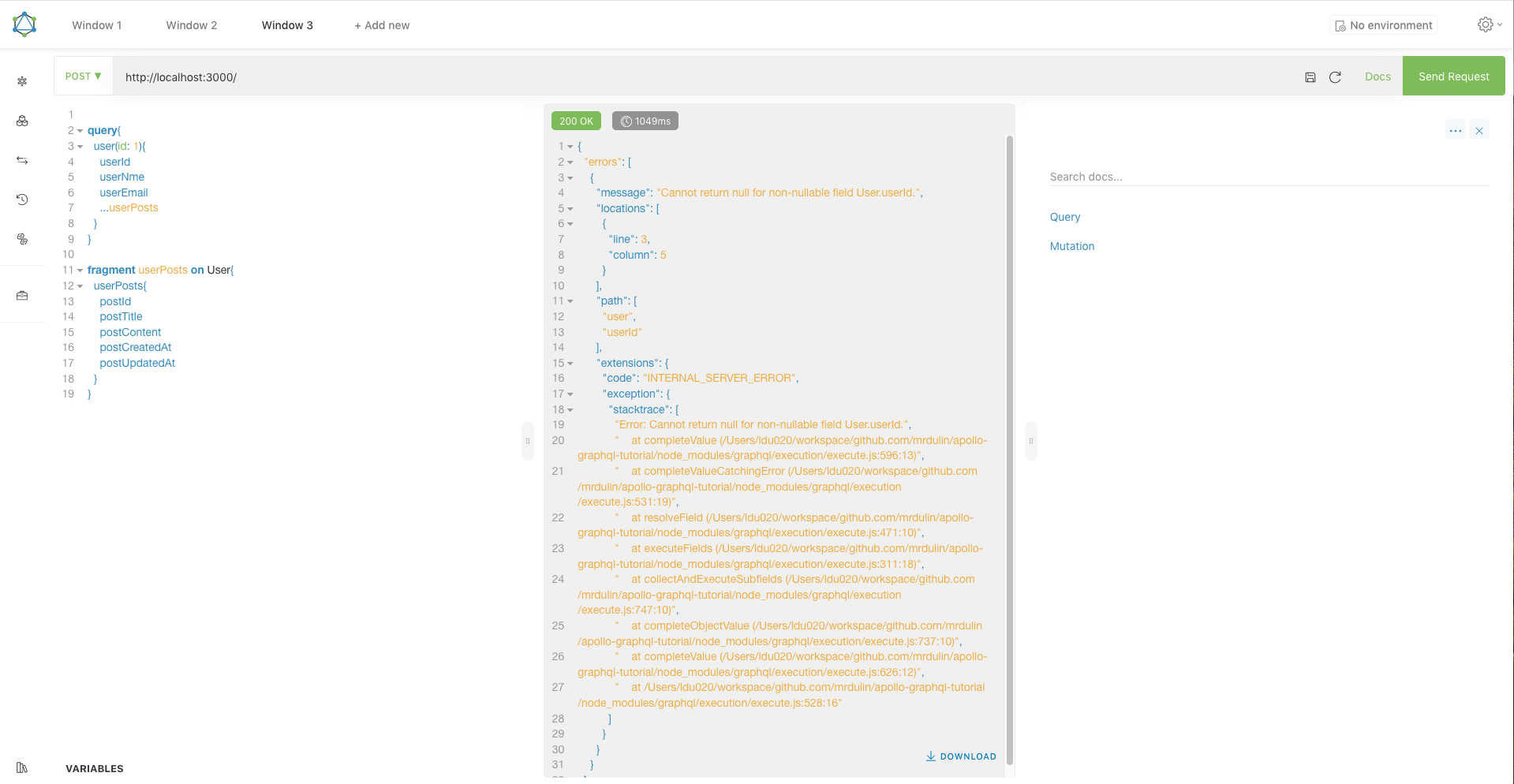
客户端发起一个Query,通过id查找user,以及属于该user的posts,该查询会调用GraphQL Service定义的Query.user resolver和User.userPosts resolver。然而,得到了一个错误:
Cannot return null for non-nullable field User.userId.
不能给User Type的userId字段返回null值,因为userId字段的类型是ID!,!符号表示该字段的resolver必须返回非null值。出现这个错误也很容易理解,因为数据库users表的字段是下划线命名的,可以在Query.user resolver中打印出SQL Query查询的结果:
{ method: 'raw',
sql: 'select * from users where user_id = ?;',
bindings: [ '1' ],
options: {},
__knexQueryUid: 'ce93c44c-5db3-47e2-9229-ee413bcb09d6' }
[2019-08-06T13:05:50+08:00][debug]: {
"service": "apollo-graphql-tutorial",
"arguments": {
"record": {
"user_id": 1,
"user_nme": "Eleanora Russel",
"user_email": "Dominique42@yahoo.com",
"user_first_nme": "Jakob",
"user_last_nme": "DuBuque",
"user_friend_ids": [
2,
3
]
}
},
"message": "record",
"timestamp": "2019-08-06T13:05:50+08:00"
}打印的日志中,record即为SQL Query查询的结果。为了解决字段转换为题,这时候前面提到的Knex.js的两个hooks该登场了。Knex配置如下:
const config: knex.Config = {
client: 'pg',
connection,
pool: {
min: 2,
max: 10,
},
debug: process.env.NODE_ENV !== 'production',
postProcessResponse: (result, queryContext) => {
logger.debug(result, { context: 'postProcessResponse' });
if (result.rows) {
return humps.camelizeKeys(result);
}
return humps.camelizeKeys(result);
},
};对于postProcessResponse,当使用knex.raw()等API时,查询结果集中行数据都在rows字段,当使用knex('tableName').select().where()等API时,行数据就是result字段,当然这里是几个简单场景,我并没有覆盖所有场景,只做引申。humps.camelizeKeys()方法会将对象,对象数组中的字段全部转换为驼峰形式。再次在客户端发起Query进行测试,结果如下:
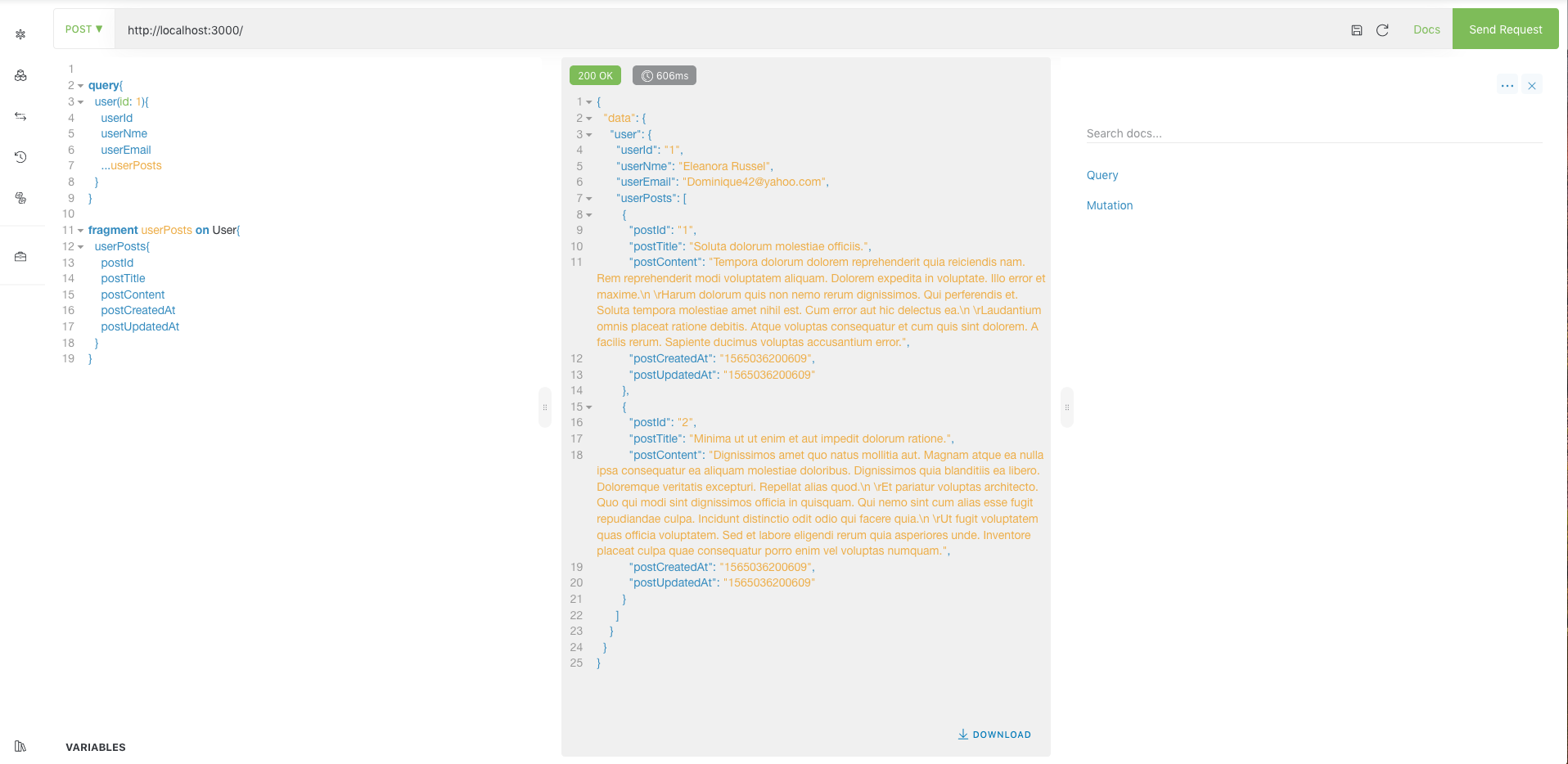
SQL Query查询的user数据日志如下:
{ method: 'raw',
sql: 'select * from users where user_id = ?;',
bindings: [ '1' ],
options: {},
__knexQueryUid: '3d922fac-e09b-42b7-bc39-dc3c8dd7c42d' }
[2019-08-06T13:26:03+08:00][debug]: {
"service": "apollo-graphql-tutorial",
"arguments": {
"record": {
"userId": 1,
"userNme": "Eleanora Russel",
"userEmail": "Dominique42@yahoo.com",
"userFirstNme": "Jakob",
"userLastNme": "DuBuque",
"userFriendIds": [
2,
3
]
}
},
"message": "record",
"timestamp": "2019-08-06T13:26:03+08:00"
}可见,user数据从数据库中查询出来后,进过postProcessResponse的处理,所有字段都转换为了驼峰形式,userPosts字段返回的数据同理。
再来看下GraphQL Mutation,客户端发起mutation,返回错误:
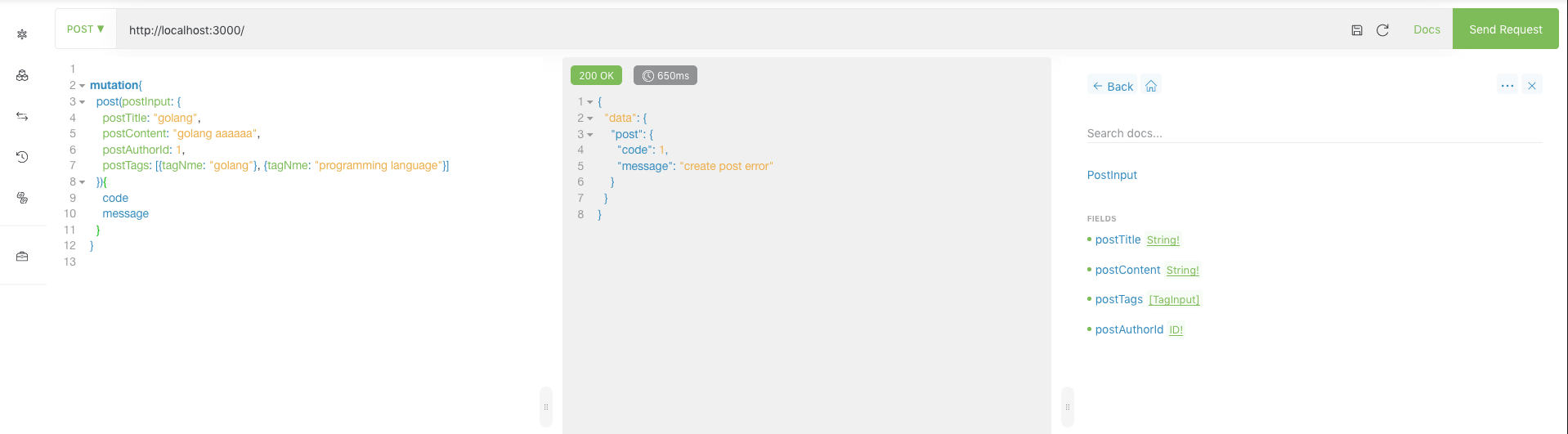
GraphQL Service应用程序报错日志如下:
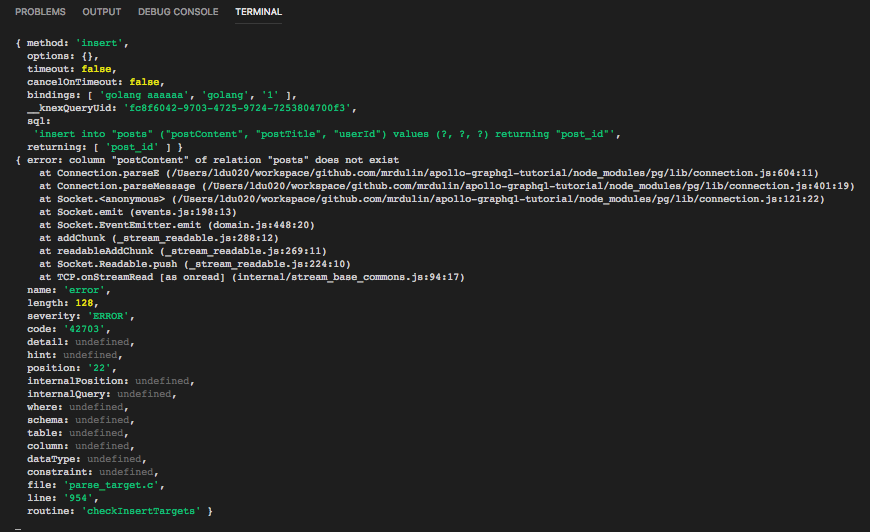
error: column "postContent" of relation "posts" does not exist
postContent这个字段在posts表中不存在,posts表中是post_content字段,因此需要进行转换,使用Knex.js提供的wrapIdentifier方法,实现如下:
const config: knex.Config = {
client: 'pg',
connection,
pool: {
min: 2,
max: 10,
},
debug: process.env.NODE_ENV !== 'production',
wrapIdentifier: (value, origImpl, queryContext) => {
logger.debug(`[wrapIdentifier] value = ${value}`);
const identifier = origImpl(humps.decamelize(value));
logger.debug(`[wrapIdentifier] identifier = ${identifier}`);
return identifier;
},
postProcessResponse: (result, queryContext) => {
logger.debug(result, { context: 'postProcessResponse' });
if (result.rows) {
return humps.camelizeKeys(result);
}
return humps.camelizeKeys(result);
},
};humps.decamelize()方法将标识符(identifier)由驼峰命名形式转换为下划线命名形式。再次在客户端发起mutation测试,结果如下:
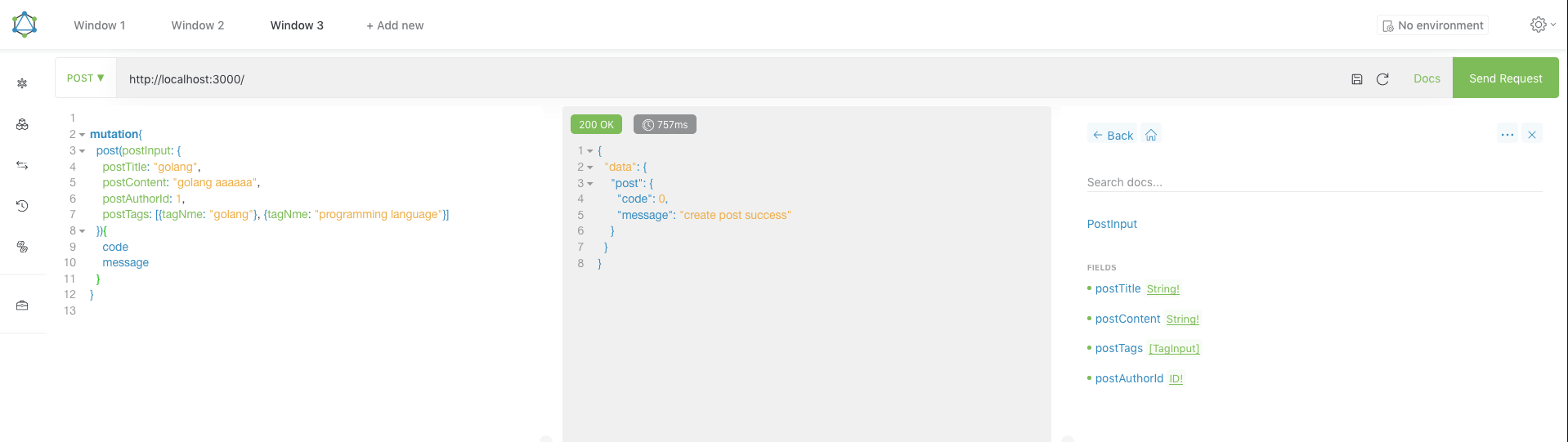
创建post成功,我们来看下wrapIdentifier打印的日志:
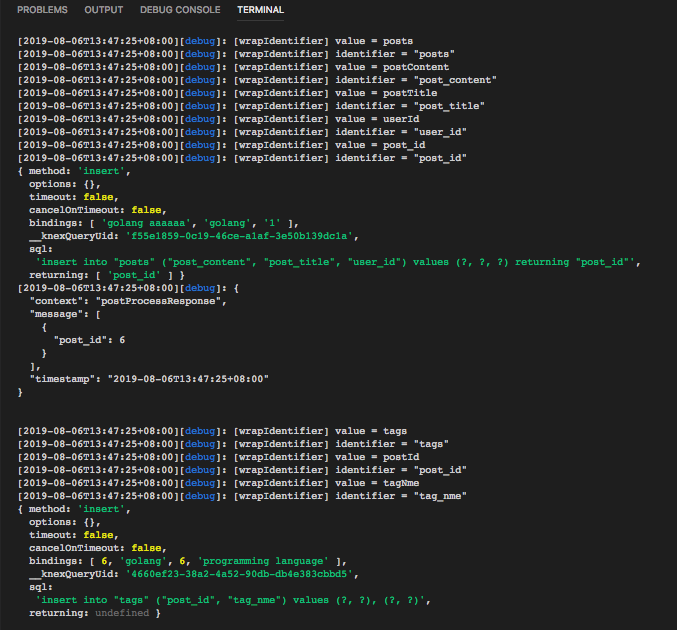
可以看到, 在发起GraphQL mutation时,后端执行创建post事务,插入数据之前,wrapIdentifier 方法将标识符:posts, postContent, postTitle, userId, post_id转换为"posts", "post_content", "post_title", "user_id", "post_id",因此,最终的SQL Query语句如下:
'insert into "posts" ("post_content", "post_title", "user_id") values (?, ?, ?) returning "post_id"'对于创建tag,同理,最终的SQL Query语句如下:
'insert into "tags" ("post_id", "tag_nme") values (?, ?), (?, ?)'这两个方法影响的范围是全局的,如果针对某个SQL Query,我们并不想进行字段转换,可以通过queryContext传递一些信息,然后根据该信息来决定是否进行字段转换。
至此,就完成了使用Knex.js Query Builder的hooks完成数据库表字段和GraphQL Schema字段的转换。当然,转换字段的方法不限于此,也可以使用ORM完成,不同的库和框架有不同的方法实现。
参考
源码地址
https://github.com/mrdulin/apollo-graphql-tutorial/tree/master/src/fields-conversion-with-knex