|
3108 | 3108 | "\n", |
3109 | 3109 | "---\n", |
3110 | 3110 | "\n", |
| 3111 | + "[](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/how-to-finetune-florence-2-on-detection-dataset.ipynb)\n", |
3111 | 3112 | "[](https://blog.roboflow.com/florence-2/)\n", |
3112 | 3113 | "[](https://arxiv.org/abs/2311.06242)\n", |
3113 | 3114 | "\n", |
3114 | 3115 | "Florence-2 is a lightweight vision-language model open-sourced by Microsoft under the MIT license. The model demonstrates strong zero-shot and fine-tuning capabilities across tasks such as captioning, object detection, grounding, and segmentation.\n", |
3115 | 3116 | "\n", |
3116 | | - "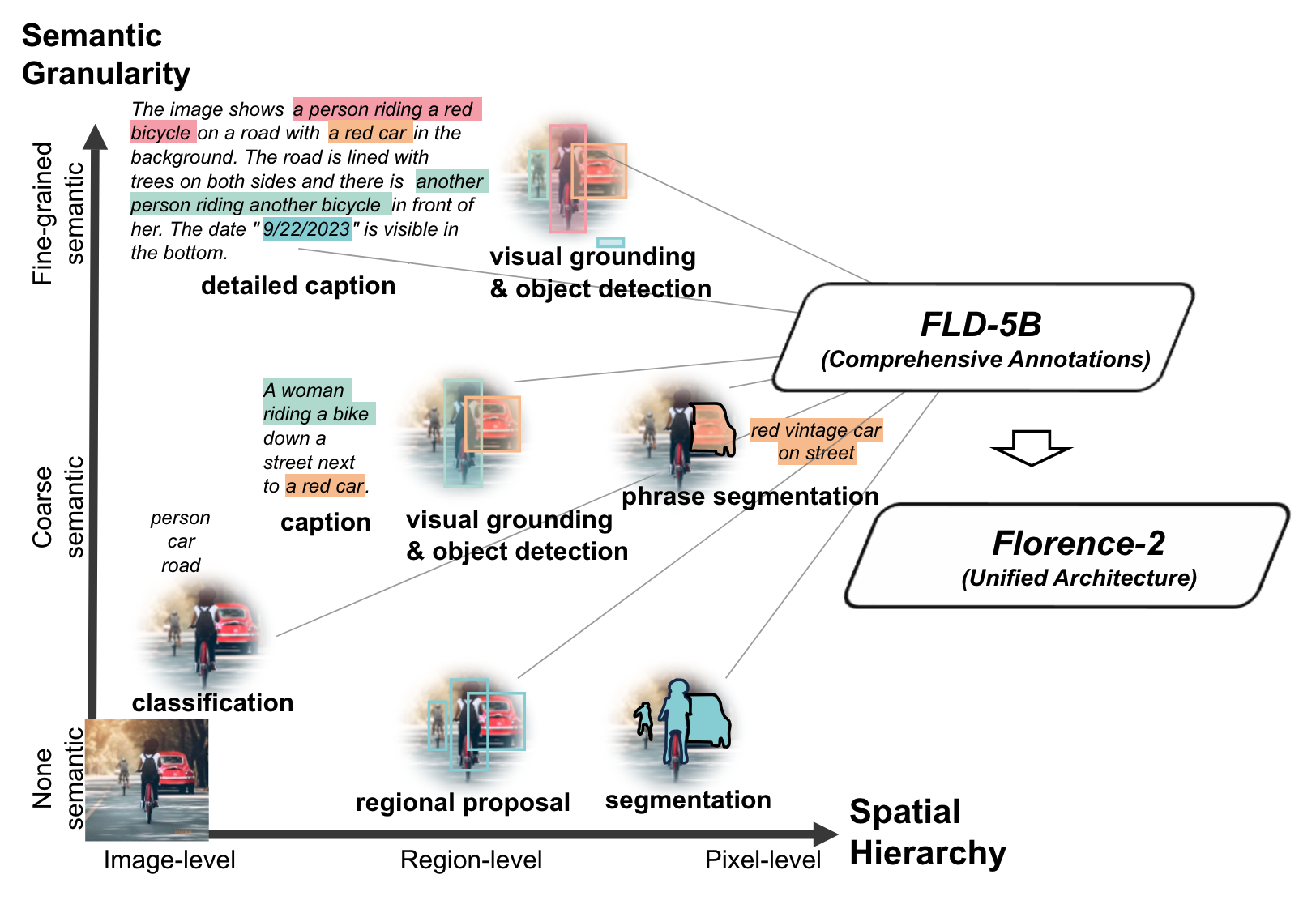\n", |
3117 | | - "\n", |
3118 | | - "*Figure 1. Illustration showing the level of spatial hierarchy and semantic granularity expressed by each task. Source: Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks.*\n", |
3119 | | - "\n", |
3120 | 3117 | "The model takes images and task prompts as input, generating the desired results in text format. It uses a DaViT vision encoder to convert images into visual token embeddings. These are then concatenated with BERT-generated text embeddings and processed by a transformer-based multi-modal encoder-decoder to generate the response.\n", |
3121 | 3118 | "\n", |
3122 | | - "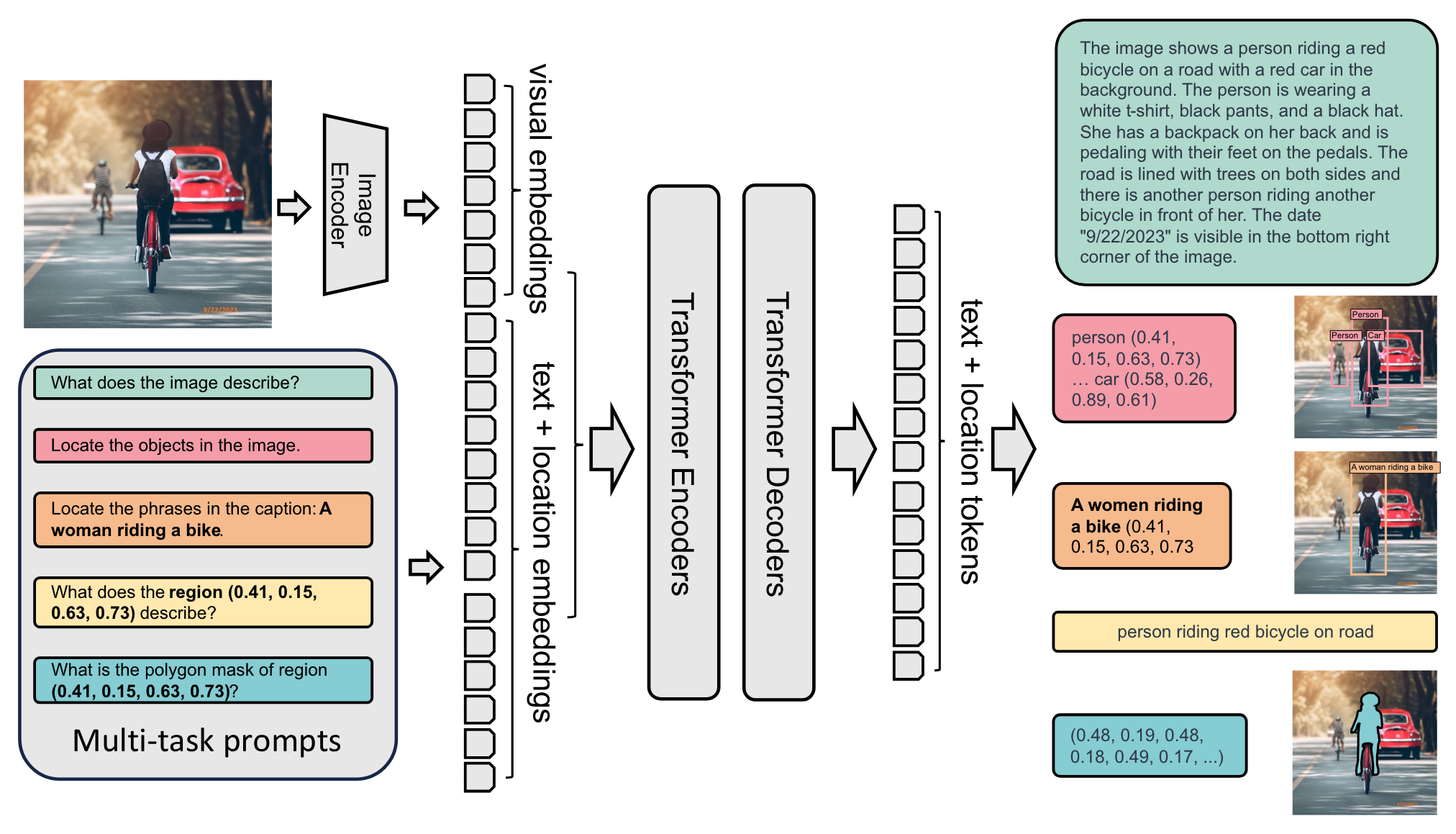\n", |
3123 | | - "\n", |
3124 | | - "*Figure 2. Overview of Florence-2 architecture. Source: Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks.*\n", |
| 3119 | + "\n", |
3125 | 3120 | "\n" |
3126 | 3121 | ], |
3127 | 3122 | "metadata": { |
|
5296 | 5291 | { |
5297 | 5292 | "cell_type": "markdown", |
5298 | 5293 | "source": [ |
5299 | | - "# Congratulations\n", |
| 5294 | + "<div align=\"center\">\n", |
| 5295 | + " <p>\n", |
| 5296 | + " Looking for more tutorials or have questions?\n", |
| 5297 | + " Check out our <a href=\"https://github.com/roboflow/notebooks\">GitHub repo</a> for more notebooks,\n", |
| 5298 | + " or visit our <a href=\"https://discord.gg/GbfgXGJ8Bk\">discord</a>.\n", |
| 5299 | + " </p>\n", |
| 5300 | + " \n", |
| 5301 | + " <p>\n", |
| 5302 | + " <strong>If you found this helpful, please consider giving us a ⭐\n", |
| 5303 | + " <a href=\"https://github.com/roboflow/notebooks\">on GitHub</a>!</strong>\n", |
| 5304 | + " </p>\n", |
5300 | 5305 | "\n", |
5301 | | - "⭐️ If you enjoyed this notebook, [**star the Roboflow Notebooks repo**](https://https://github.com/roboflow/notebooks) (and [**supervision**](https://github.com/roboflow/supervision) while you're at it) and let us know what tutorials you'd like to see us do next. ⭐️" |
| 5306 | + "</div>" |
5302 | 5307 | ], |
5303 | 5308 | "metadata": { |
5304 | 5309 | "id": "ag0XROk7fcd_" |
|
0 commit comments