Intro to Zarr & Xarray

Zarr is a file format for storing multi-dimensional arrays that is optimized for large datasets in cloud computing environments. It is similar in concept to Cloud Optimized Geotiffs and Cloud Optimized Point Clouds, but for large multi-dimensional arrays. When stored in object cloud storage, portions of Zarr files (known as chunks) can be streamed into client applications like a jupyter notebook for analysis. This allows us to work with datasets without having to download them to our local computer.
In the geopspatial world, Zarr format is an efficient way to store and share large array datasets. One example could be hyperspectral imagery where the X and Y dimensions represent geographic coordinates, and the 3rd dimension represents hundreds of spectral bands.

Another example for Zarr is meteorological or weather data across the geographic space. The X and Y dimensions could show the variable temperature, and the 3rd dimension could be time-steps (perhaps hundreds of them).

Zarr is like NetCDF-4 in capturing and expressing metadata and data, but it is more flexible than Parquet because it allows for chunking along any dimension. Zarr arrays function like NumPy arrays, but the data is divided into chunks and compressed. It provides similar functionality to HDF5 but with additional flexibility. Zarr offers powerful compression options, supports multiple data store backends, and can read/write NumPy arrays in parallel.
Here are some of the benefits of using Zarr:
- Efficient for large datasets
- Well-suited for cloud computing environments
- Chunked format
- Compressed format
- Hierarchical format
- Versioning support
- Portable format
Xarray is the python library you use to work with Zarr format. Xarray is an open source project in Python that extends Pandas, to handle multidimensional data structures that are used in the physical sciences. Xarray integrates labels in the form of dimensions, coordinates and attributes to multidimensional arrays.
Xarray expands on the capabilities on NumPy arrays, providing a lot of streamlined data manipulation. It is similar in that respect to Pandas, but whereas Pandas excels at working with dataframes, Xarray is focused on N-dimensional arrays of data (i.e. grids). Its interface is based largely on the netCDF data model (variables, attributes, and dimensions), but it goes beyond the traditional netCDF interfaces to provide functionality similar to netCDF-java’s Common Data Model (CDM).
Xarrays have two core data structures:
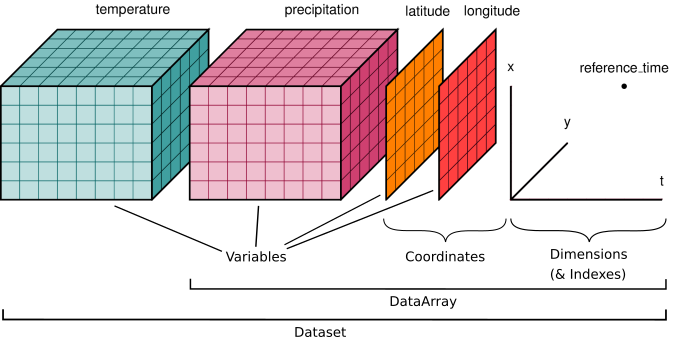
- DataArray, which is a N-dimensional array with labeled coordinates and dimensions. It is a N-dimenisonal generalization of a Pandas.Series.
- Dataset, which is a multidimensional in-memory array database.
The following is Daymet climate data from NASA. Daymet provides gridded (1 km x 1 km) estimates of daily weather data across North America. Variables include the following parameters: minimum temperature, maximum temperature, precipitation, shortwave radiation, vapor pressure, snow water equivalent, and day length.
Here is what the Daymet Zarr data looks like when queried using Xarray.

Here is what a single variable (precipitation) looks like.

xarray.DataArray is xarray’s implementation of a labeled, multi-dimensional array. It has several key properties:
- values: a numpy.ndarray holding the array’s values
- dims: dimension names for each axis (e.g., ('x', 'y', 'z'))
- coords: a dict-like container of arrays (coordinates) that label each point (e.g., 1-dimensional arrays of numbers, datetime objects or strings)
- attrs: dict to hold arbitrary metadata (attributes)
Xarray uses dims and coords to enable its core metadata aware operations. Dimensions provide names that xarray uses instead of the axis argument found in many numpy functions. Coordinates enable fast label based indexing and alignment, building on the functionality of the index found on a pandas DataFrame or Series.
DataArray objects also can have a name and can hold arbitrary metadata in the form of their attrs property. Names and attributes are strictly for users and user-written code: xarray makes no attempt to interpret them, and propagates them only in unambiguous cases.
For netDCF and IO: There is a set of optional dependencies when installing Xarray:
For accelerating Xarray:
- scipy for enabling interpolation features for xarray objects.
- bottleneck fast NumPy functions for xarray.
For parallel computing:
- dask.array for parallel computing in Python.
- Xarray Documentation.
- Xarray Tutorial
- Xarray User Guide
- Xarray API Reference
- Xarray. Project Pythia.
- Introduction to Python - ARGO float data. Ocean Data Labs. Rutgers University.

