本项目旨在通过基于规则的方法,从中文文本中提取知识三元组,构建一个高效的知识挖掘框架。项目基于 LTP 中文 NLP 技术,结合分词、词性标注和规则匹配,支持将知识三元组存储到 Neo4j 数据库或储存为 JSON 文件中。
LTP/
├── main.py # 主程序入口
├── model.py # 选择/加载LTP预训练模型以及自定义词典
├── preprocessor.py # 文本预处理模块
├── segmenter.py # 分词与词性标注模块
├── rules/ # 规则集
│ ├── base_rules.py # 20个基础规则
│ └── additional_rules.py # 可扩展的特殊规则(待建设)
├── extractor.py # 知识抽取逻辑
├── storage.py # 知识存储模块
├── test_demo.py # 对测试文本进行知识抽取的demo
└── data.txt # 测试文本(自行添加)目前只写了从csv读入的版本,具体使用方法如下:
首先需要从LTP的仓库下载预训练分词模型:https://github.com/HIT-SCIR/ltp。
将model.py中的模型路径替换为本地的路径。
下载时可优先选择small和Legacy,我自己使用的就是这两款,在词性标注上非常实用。
_model = LTP("D:/LTP/small") # 替换为自己下载的模型文件夹路径如需测试笔者仓库里提供的demo_data.csv的抽取效果,可在LTP/直接下运行:
python main.py或者可以在LTP/下创建自定义测试样例data.txt,然后运行test_demo.py,测试抽取效果。
如需用本框架对自己的数据进行知识抽取,可运行:
python main.py --csv_file 你的csv文件路径 --text_column 你保存文本的列名如需开启本地neo4j存储,请自行修改main.py的参数设置:
parser.add_argument('--csv_file', type=str, default='D:/CodeField/knowledge_extraction/demo_data.csv', help='Path to the CSV file.')
parser.add_argument('--text_column', type=str, default='正文', help='Name of the column containing text.')
parser.add_argument('--need_neo4j', type=bool, default=False, help='Whether to save the results to Neo4j database.')
parser.add_argument('--neo4j_uri', type=str, default='bolt://localhost:7687', help='URI for the Neo4j database.')
parser.add_argument('--neo4j_user', type=str, default='neo4j', help='Username for the Neo4j database.')
parser.add_argument('--neo4j_password', type=str, default='passw0rd', help='Password for the Neo4j database.')
parser.add_argument('--neo4j_database', type=str, default='neo4j', help='Database name for the Neo4j database.')
parser.add_argument('--output_file', type=str, default='knowledge.json', help='Output file to save the results.')提取规则
以下是项目中实现的提取规则:
- 提取广泛的动词和宾语之间的关系,例如 "A 动作 B",其中A和B都是名词,且B后无动词/形容词/助词。
- 提取 "A 是 B" 形式的描述性关系,其中A和B都是名词,且B后无动词/形容词/助词。
- 提取形容词修饰名词的关系,例如 "美丽/a 的/u 花/n" 提取为 (美丽, 修饰, 花)。
- 提取时间或地点与动词及宾语之间的修饰关系。例如,"昨天/t 北京/ns 举行/v 会议/n" 提取为[('昨天', '举行', '会议'), ('北京', '举行', '会议')]。
- 提取动词和地点之间的关系。例如,对于"台风抵达了上海" 提取为 (台风, 抵达, 上海)。
- 提取动词和时间之间的关系。
- 提取 "A 具有 B" 的关系。
- 提取 "A 包括 B" 的关系。
- 提取 "A 拥有 B" 的关系。(实际语境中789这三个近义词并不一定能互用)
- 提取 "A 需要 B" 的关系。
- 提取 "A 导致 B" 的因果关系,包括多种结构形式,其中B可能是词或短语。例如,对于"下雨导致道路湿滑",提取出的三元组为 ('下雨', '导致', '道路湿滑')。
- 提取第二类名词与形容词之间的修饰关系,例如"国家/n 富强/a" 提取为 (富强, 修饰, 国家)。
- 提取人物与地点的分类关系,根据词性标注是ns或nh直接获得。例如 "张三 是 人物","北京 是 地点"。
- 食物提取规则:提取与 "吃" 或 "喝" 动作相关的名词,以及在只修饰食物的形容词后的名词,并标记为 "食物"。
- 提取 "名词/人物 + 喜欢 + 动词短语 或 动宾结构"。
- 提取 "A 是 B 的 C" 结构,例如"这款汽车是小米的杀手锏"。
- 提取"A 因为 B" 的因果关系,包括多种结构形式,其中B可能是词或短语。例如,对于"车祸因为司机开车喝酒",提取出的三元组为 ('车祸', '因为', '司机开车喝酒')。
- 提取所有的 "A/ni" 为 "A 是 机构",直接根据词性标注获得。
- 提取所有的 "A/i" 为 "A 是 成语",直接根据词性标注获得。
- 提取相似关系,包括:"A 就像 B"、"A 好像 B"、"A 如 B"、"A 和 B 很像"和其他类似表达提取为 (A, 相似于, B)。
更具体的细节在
rules/base_rules.py中。
规则实现 规则基于正则表达式来实现:
虽然LTP进行词性标注得到的结果是两个列表,但为了方便进行匹配,我选择将两个列表合并为了一个字符串。
例如,对“我喜欢吃KFC”分词结果为:
result.cws[0]: ['我', '喜欢', '吃', 'KFC'] result.pos[0]: ['r', 'v', 'v', 'n']
被我处理为了:我/r 喜欢/v 吃/v KFC/n
然后,再使用 Python 的 re 模块进行模式匹配和提取,匹配模式支持丰富的词性标注信息。
规则代码文件位于 rules/base_rules.py 中。
-
完善 additional_rules.py 文件,引入一些对特殊领域文本的special rules,支持更多样化的知识抽取需求以及挖掘更深层次的关系。
-
优化规则匹配效率,处理更大规模的文本数据。
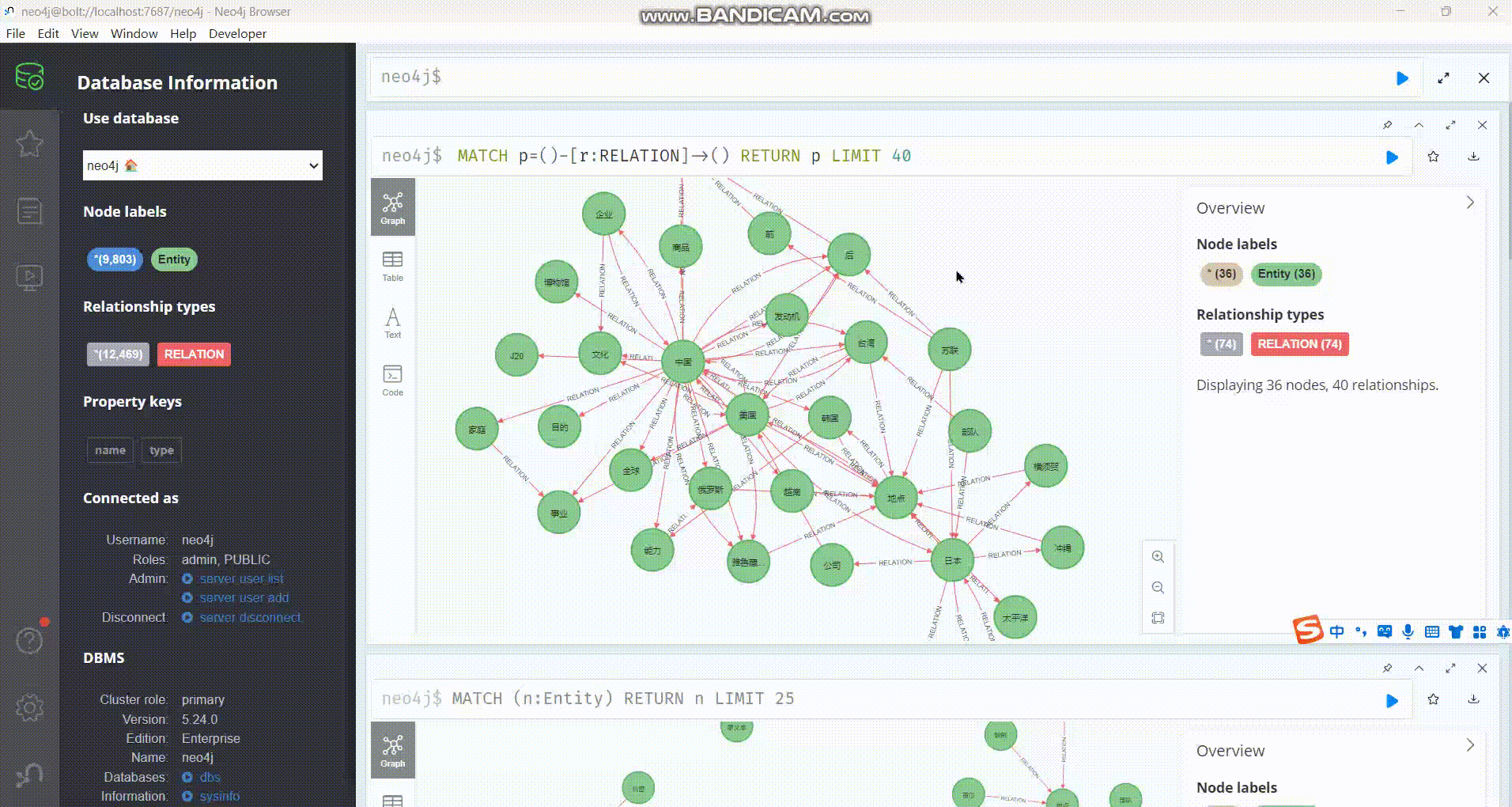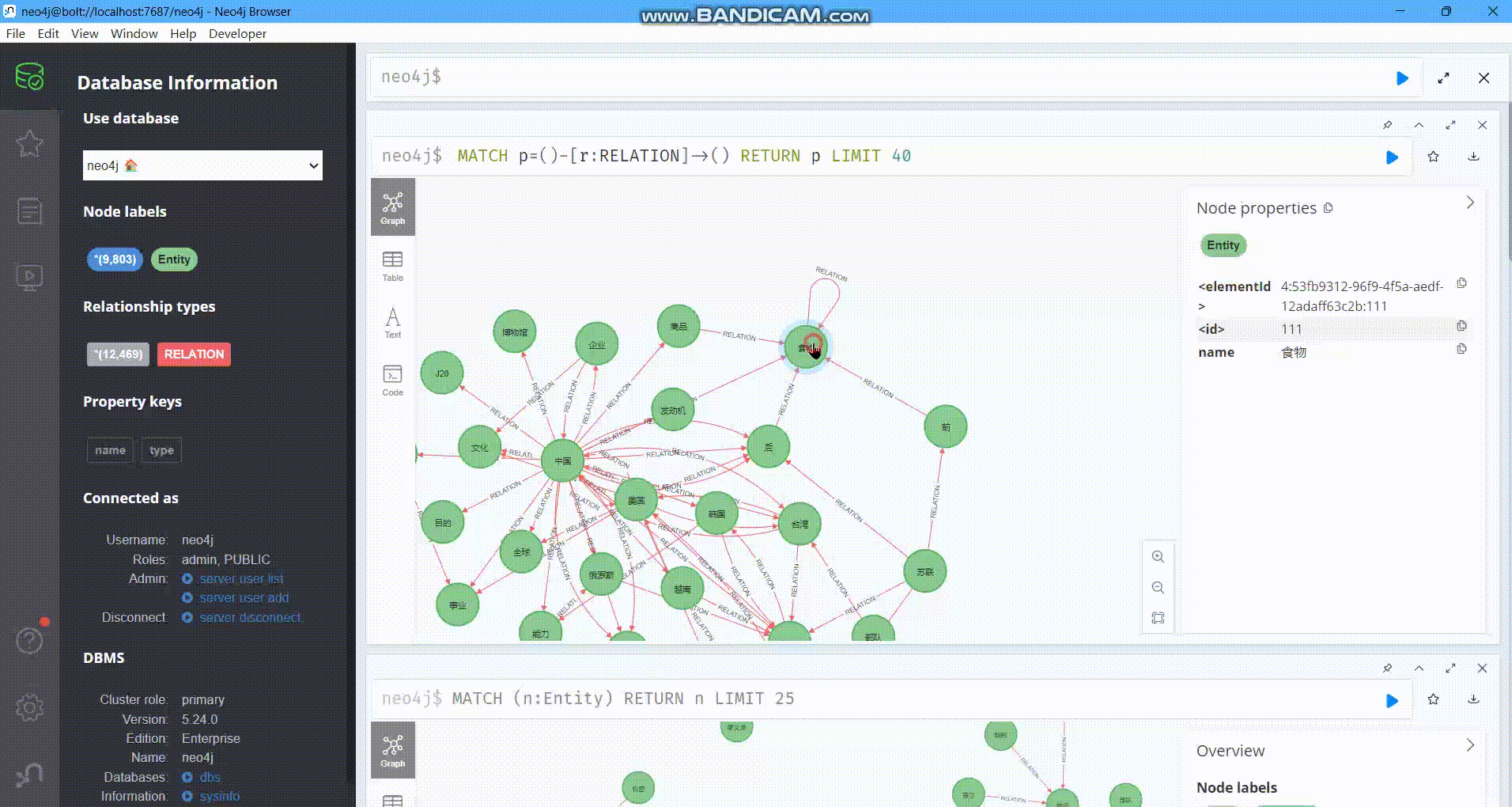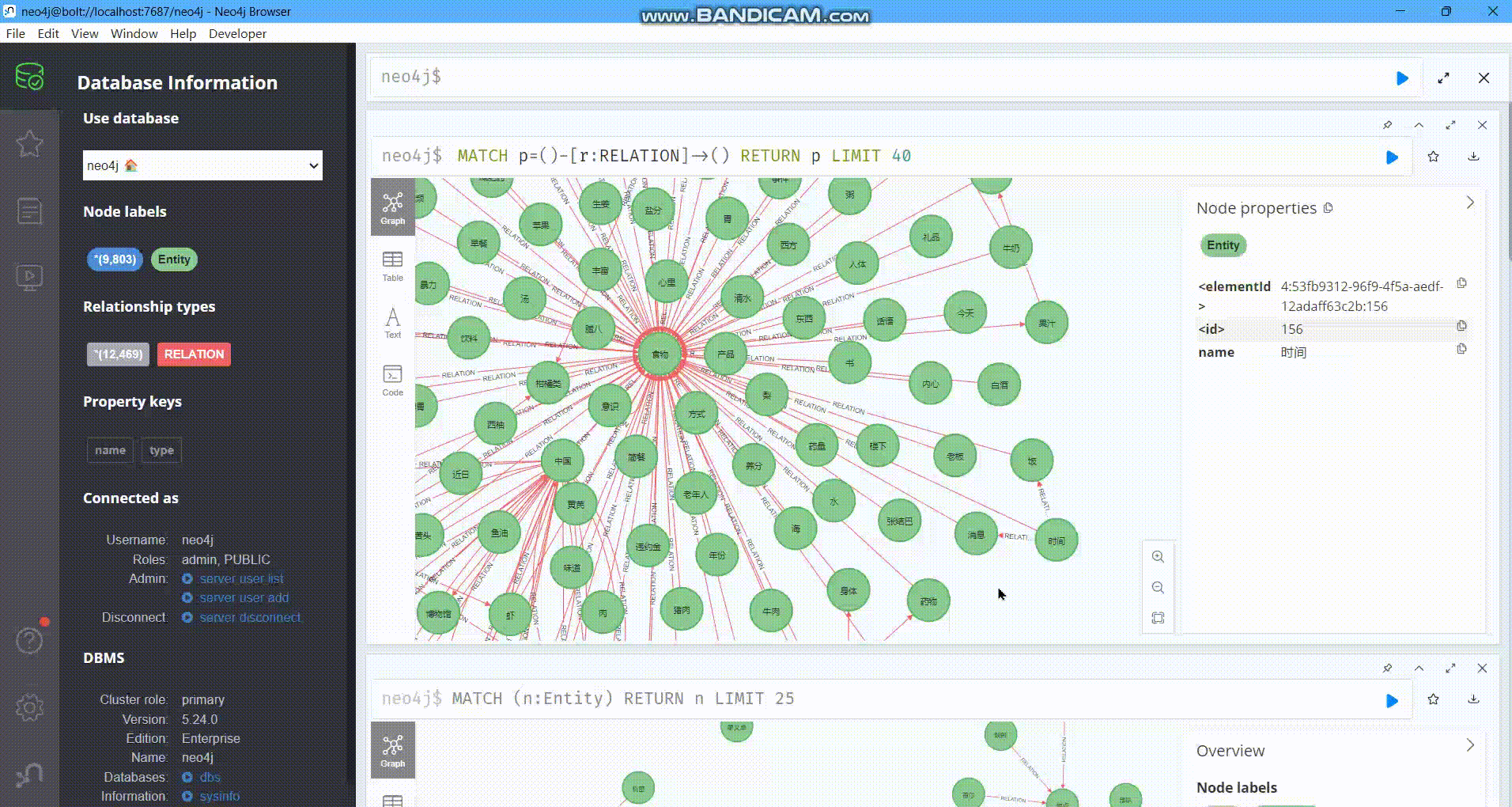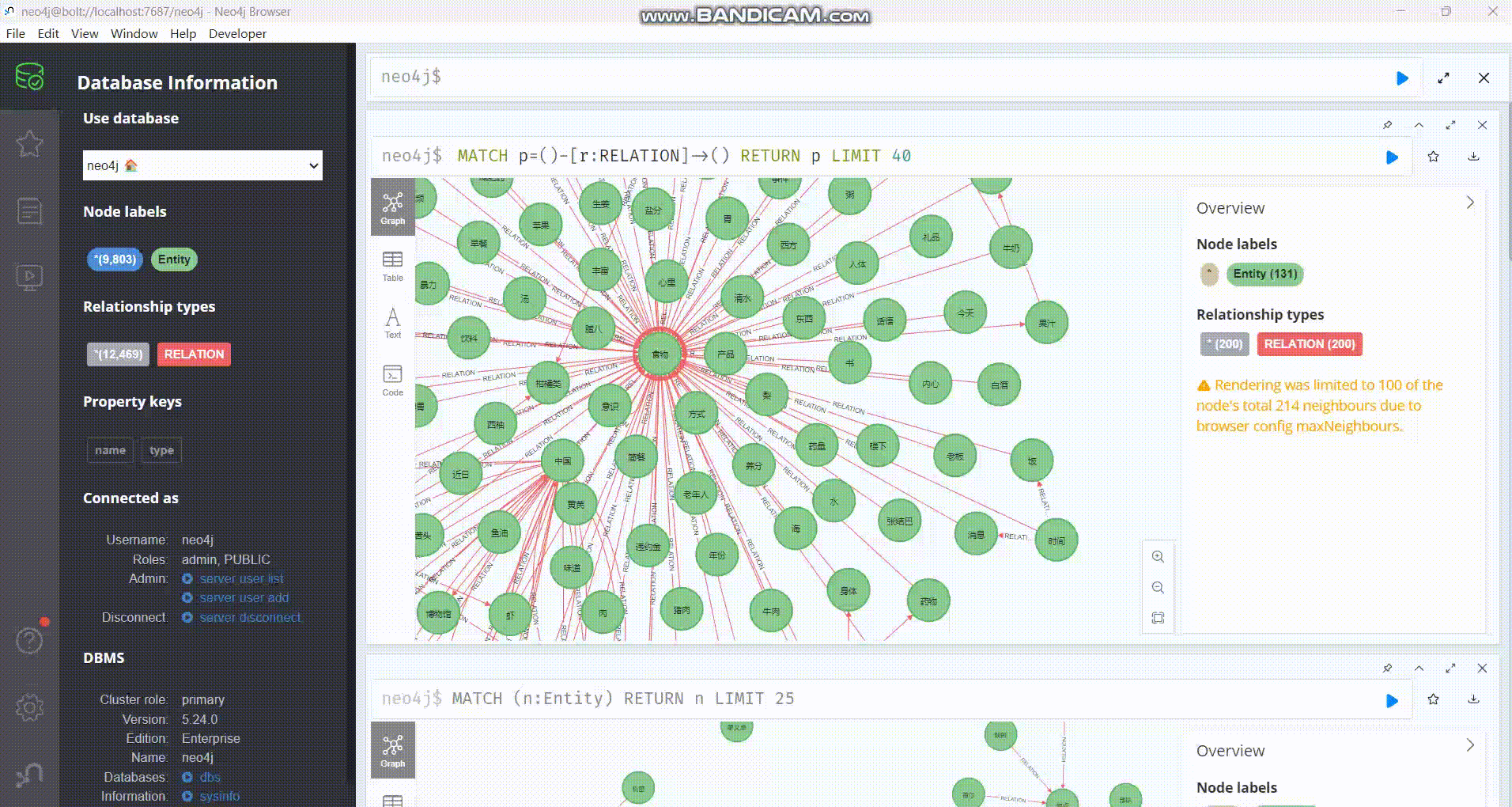
下图展示了生成的知识图谱的一小部分:
https://picbed.octalzhihao.top/img/tempp.gif
{kind=link}
欢迎社区用户参与贡献!请提交 PR 或 issue 与我们交流。
本项目 遵循 MIT License 开源协议。