A collection of tricks to simplify and speed up transformer models:
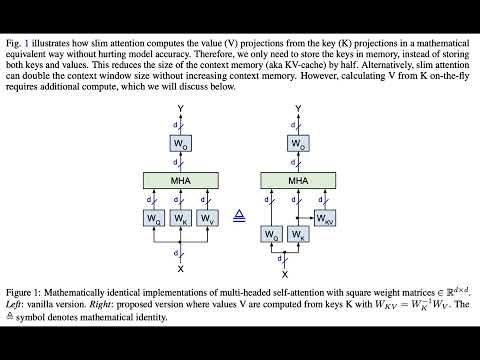
- Slim attention: paper, video, podcast, notebook, code-readme, 🤗 article, reddit
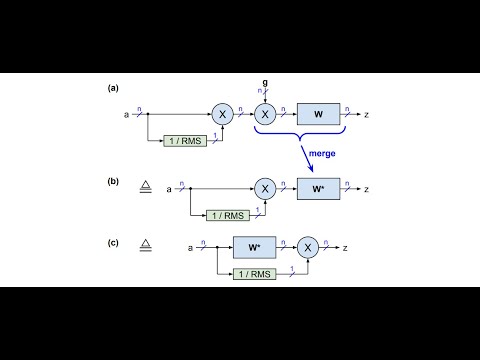
- FlashNorm: paper, video, podcast, notebook, code-readme
- Matrix-shrink [work in progress]: paper
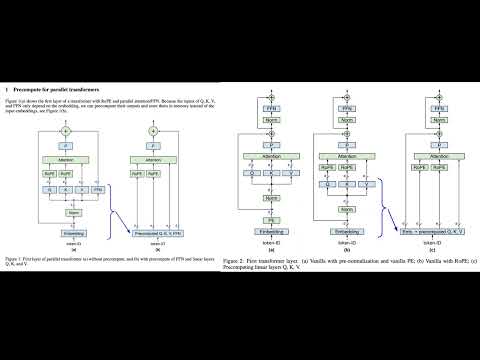
- Precomputing the first layer: paper, video, podcast
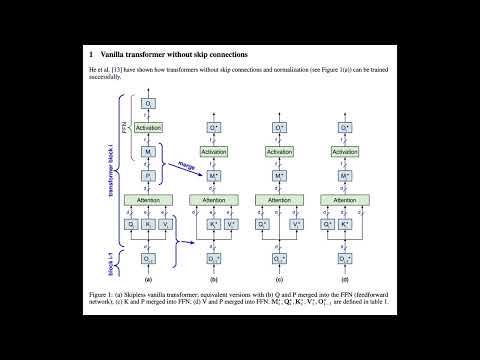
- KV-weights only for skipless transformers: paper, video, podcast, notebook
These transformer tricks extend a recent trend in neural network design toward architectural parsimony, in which unnecessary components are removed to create more efficient models. Notable examples include RMSNorm’s simplification of LayerNorm by removing mean centering, PaLM's elimination of bias parameters, and decoder-only transformer's omission of the encoder stack. This trend began with the original transformer model's removal of recurrence and convolutions.
For example, our FlashNorm removes the weights from RMSNorm and merges them with the next linear layer. And slim attention removes the entire V-cache from the context memory for MHA transformers.
Install the transformer tricks package:
pip install transformer-tricksAlternatively, to run from latest repo:
git clone https://github.com/OpenMachine-ai/transformer-tricks.git
python3 -m venv .venv
source .venv/bin/activate
pip3 install --quiet -r requirements.txtFollow the links below for documentation of the python code in this directory:
The papers are accompanied by the following Jupyter notebooks:
- Slim attention:
- Flash normalization:
- Removing weights from skipless transformers:
Please subscribe to our newsletter on substack to get the latest news about this project. We will never send you more than one email per month.
We pay cash for high-impact contributions. Please check out CONTRIBUTING for how to get involved.
The Transformer Tricks project is currently sponsored by OpenMachine. We'd love to hear from you if you'd like to join us in supporting this project.