
- Introduction to Deep Learning
- Neural Networks
- Forward Propagation and Backward Propagation
- Loss Functions
- Convolutional Neural Networks (CNNs)
- R-CNN (Region-based Convolutional Neural Networks)
- Fast R-CNN
- Faster R-CNN
- Mask R-CNN
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTM) Networks
- Generative Adversarial Networks (GANs)
- Conclusion
- Appendix: Mapping Table
Deep learning is a subset of machine learning that uses artificial neural networks with many layers to model and understand complex patterns in data. It has revolutionized various fields, including computer vision, natural language processing, and speech recognition.
- Neural Networks: Inspired by the human brain, neural networks consist of interconnected layers of nodes (neurons) that process information.
- Layers: Neural networks are composed of multiple layers, including input, hidden, and output layers.
- Training: The process of adjusting the weights of the neural network to minimize the error between predicted and actual outputs.

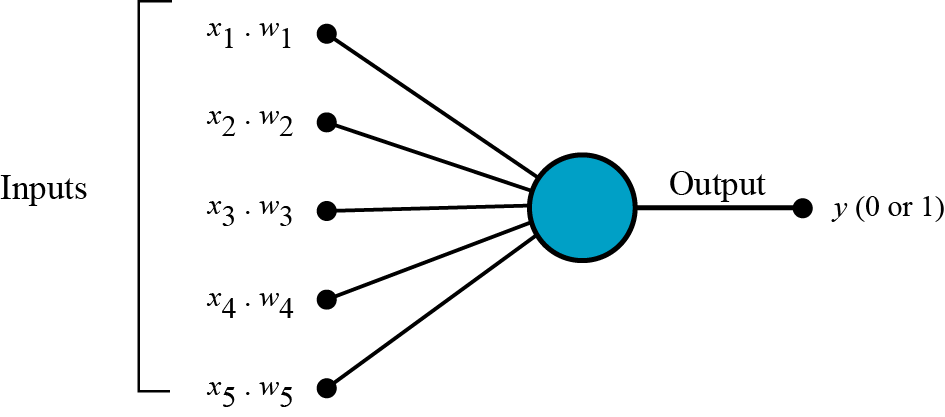
The perceptron is the simplest form of a neural network, introduced by Frank Rosenblatt in 1957. It consists of a single layer of weights that connect inputs to an output.
- Input: $ x_1, x_2, \ldots, x_n $
- Weights: $ w_1, w_2, \ldots, w_n $
- Bias: $ b $
- Output: $ y $
The output of a perceptron is given by:
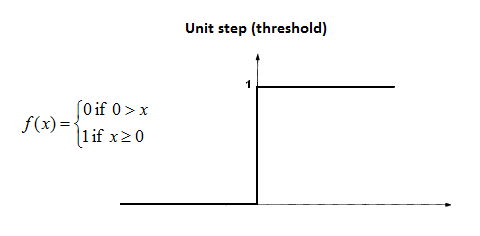
where $ f $ is an activation function.
Artificial Neural Networks (ANNs) are more complex models that consist of multiple layers of interconnected neurons. They can model complex relationships in data.
ANNs work by passing inputs through layers of neurons, where each neuron performs a weighted sum of its inputs, adds a bias, and applies an activation function.
- Input Layer: Receives the input data.
- Hidden Layers: Process the input data through multiple layers of neurons.
- Output Layer: Produces the final output.
The output of a neuron in a hidden layer is given by:
where $ z_j $ is the output of the $ j $-th neuron, $ w_{ji} $ are the weights, $ x_i $ are the inputs, $ b_j $ is the bias, and $ f $ is the activation function.
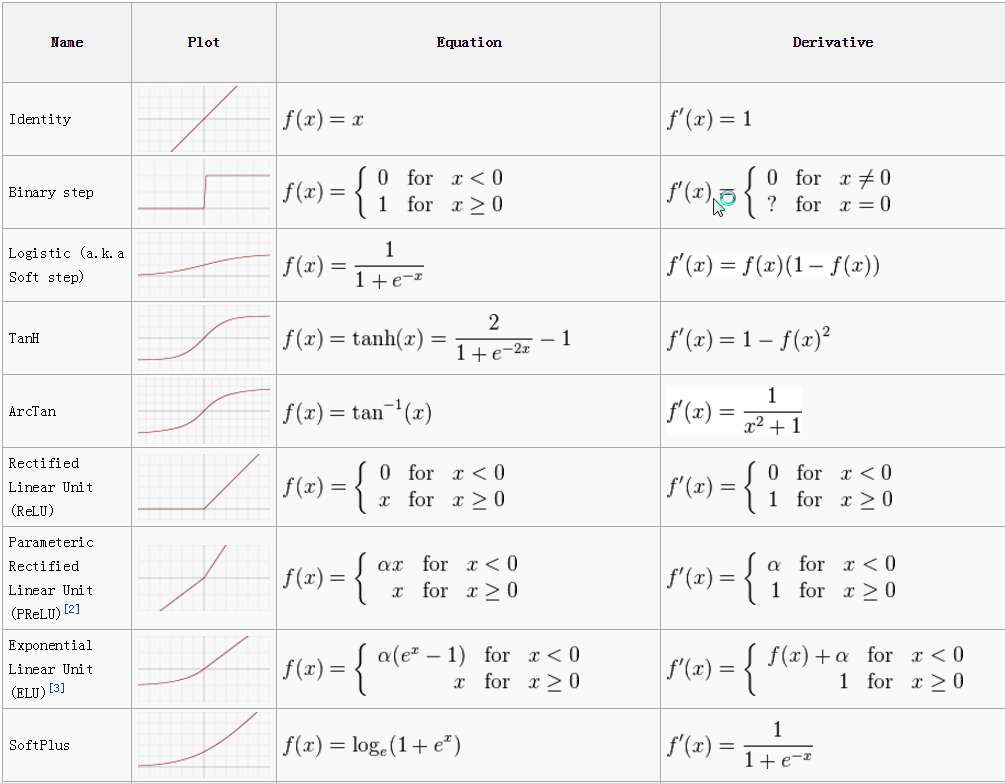
Activation functions introduce non-linearity into the model, allowing it to learn complex patterns. Common activation functions include:
-
Sigmoid: $ \sigma(x) = \frac{1}{1 + e^{-x}} $
- Use Case: Often used in the output layer for binary classification problems.
-
Tanh: $ \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $
- Use Case: Used in hidden layers to introduce non-linearity.
-
ReLU (Rectified Linear Unit): $ \text{ReLU}(x) = \max(0, x) $
- Use Case: Widely used in hidden layers for its simplicity and effectiveness in deep networks.
-
Leaky ReLU: $ \text{Leaky ReLU}(x) = \max(0.01x, x) $
- Use Case: Used to mitigate the dying ReLU problem, where neurons can get stuck in the negative region.
-
Softmax: $ \text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}} $
- Use Case: Used in the output layer for multi-class classification problems.
Optimization involves adjusting the weights of the neural network to minimize the loss function. Common optimization algorithms include:
- Gradient Descent: Updates the weights in the direction of the negative gradient of the loss function.
- Use Case: Basic optimization algorithm, but can be slow for large datasets.
- Stochastic Gradient Descent (SGD): Updates the weights using a single training example at a time.
- Use Case: Faster than gradient descent, but can be noisy.
- Mini-batch Gradient Descent: Updates the weights using a small batch of training examples.
- Use Case: Balances the speed of SGD and the stability of gradient descent.
- Adam: An adaptive learning rate optimization algorithm that combines the benefits of two other extensions of stochastic gradient descent.
- Use Case: Widely used for its efficiency and effectiveness in training deep networks.
The weight update rule for gradient descent is given by:
where $ \eta $ is the learning rate, $ L $ is the loss function, and $ \frac{\partial L}{\partial w_{ij}} $ is the gradient of the loss with respect to the weight $ w_{ij} $.
-
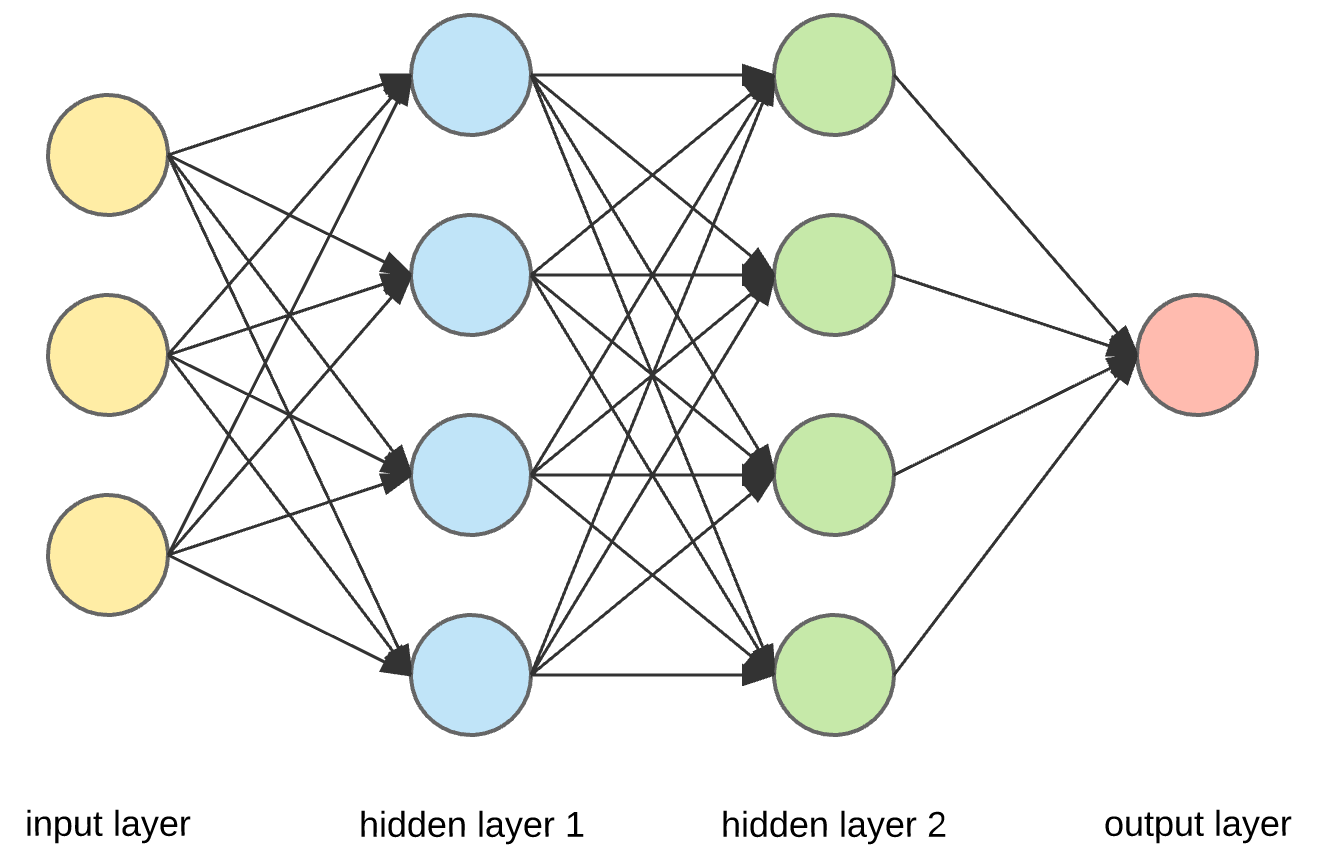
Neural Network Architecture
Basic architecture of an artificial neural network showing input layer, hidden layers, and output layer
-
Activation Functions
Visualization of common activation functions: Sigmoid, Tanh, ReLU, and Leaky ReLU
-
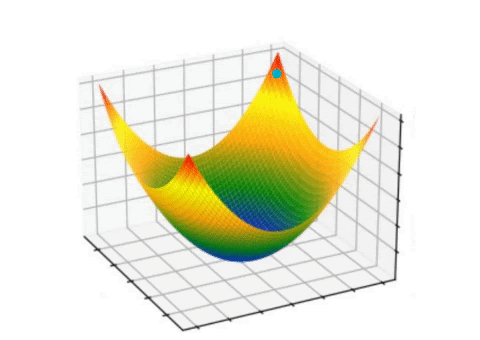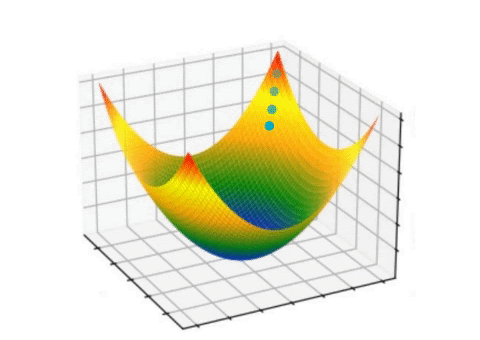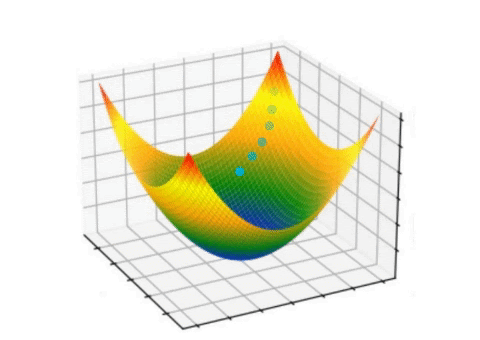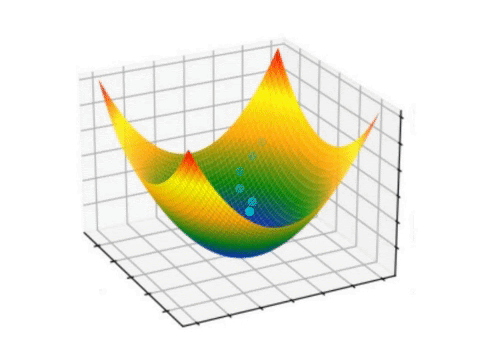
Optimization Process
Gradient descent optimization process showing how weights are updated to minimize loss
-
Forward Propagation
Forward propagation process showing how input signals propagate through the network
-
Backward Propagation
Backward propagation process showing how errors propagate backwards through the network
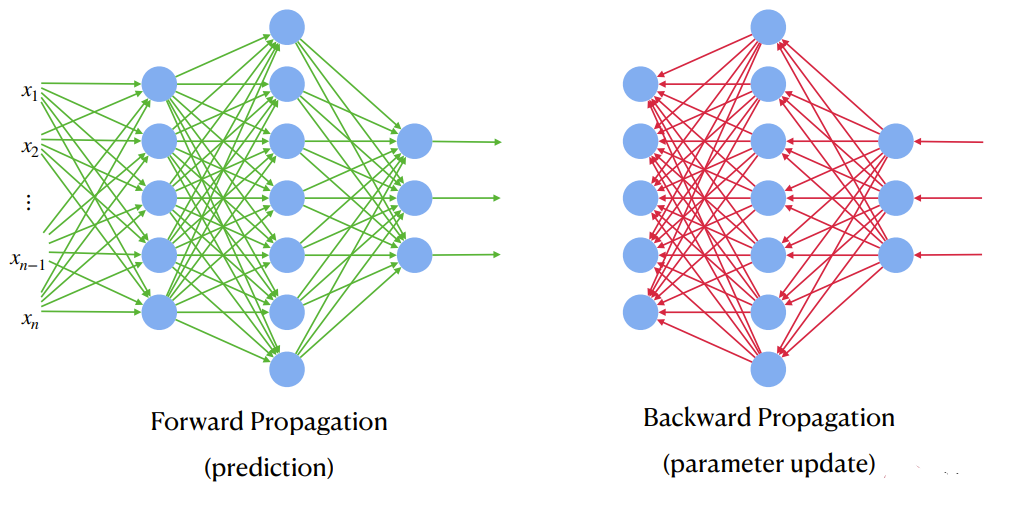
Forward propagation is the process of passing input data through the neural network to generate an output. It involves the following steps:
- Input Layer: Receive the input data.
- Hidden Layers: Compute the weighted sum of inputs, add the bias, and apply the activation function for each neuron.
- Output Layer: Generate the final output.
The output of a neuron in a hidden layer is given by:
Backward propagation is the process of adjusting the weights of the neural network to minimize the loss function. It involves the following steps:
- Compute the Loss: Calculate the loss between the predicted and actual outputs.
- Compute the Gradient: Calculate the gradient of the loss with respect to each weight using the chain rule.
- Update the Weights: Adjust the weights in the direction of the negative gradient.
The weight update rule for gradient descent is given by:
Gradient descent is an optimization algorithm that adjusts the weights of the neural network to minimize the loss function. It involves the following steps:
- Initialize the Weights: Start with random initial weights.
- Compute the Gradient: Calculate the gradient of the loss with respect to each weight.
- Update the Weights: Adjust the weights in the direction of the negative gradient.
- Repeat: Repeat the process until the loss converges.
The vanishing gradient problem occurs when the gradients become very small in the early layers of the network, making it difficult to update the weights. This can slow down the training process and make it difficult to learn long-term dependencies.
- Cause: Activation functions like sigmoid and tanh can squash the gradients to very small values.
- Solution: Use activation functions like ReLU, which do not suffer from the vanishing gradient problem.
Loss functions measure the difference between the predicted and actual outputs. They guide the optimization process by providing a signal for adjusting the weights.
-
Mean Squared Error (MSE) Loss:
- Formula: $ L = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 $
- Use Case: Regression problems.
-
Cross-Entropy Loss:
- Formula: $ L = -\frac{1}{n} \sum_{i=1}^{n} [y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i)] $
- Use Case: Binary classification problems.
-
Categorical Cross-Entropy Loss:
- Formula: $ L = -\frac{1}{n} \sum_{i=1}^{n} \sum_{j=1}^{m} y_{ij} \log(\hat{y}_{ij}) $
- Use Case: Multi-class classification problems.
-
Hinge Loss:
- Formula: $ L = \max(0, 1 - y_i \hat{y}_i) $
- Use Case: Support Vector Machines (SVMs).
-
Huber Loss:
- Formula: $ L = \begin{cases} \frac{1}{2} (y_i - \hat{y}_i)^2 & \text{if } |y_i - \hat{y}_i| \leq \delta \ \delta (|y_i - \hat{y}_i| - \frac{1}{2} \delta) & \text{otherwise} \end{cases} $
- Use Case: Robust regression problems.
| Loss Function | Use Case |
|---|---|
| Mean Squared Error (MSE) Loss | Regression problems |
| Cross-Entropy Loss | Binary classification problems |
| Categorical Cross-Entropy Loss | Multi-class classification problems |
| Hinge Loss | Support Vector Machines (SVMs) |
| Huber Loss | Robust regression problems |
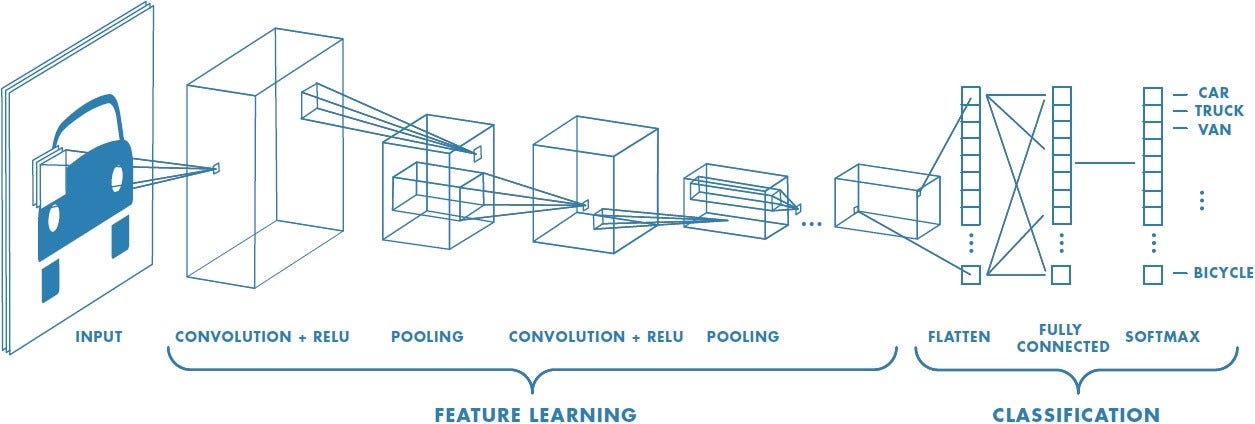
Convolutional Neural Networks (CNNs) are a type of deep learning model specifically designed for processing structured grid data like images. They use convolution operations to automatically and adaptively learn spatial hierarchies of features.
The convolution operation involves a filter (or kernel) that slides over the input image to produce a feature map.
- Filter/Kernel: A small matrix of weights that is used to detect specific features in the input image.
- Stride: The number of pixels by which the filter moves over the image.
The output of a convolution operation is given by:
where $ I $ is the input image, $ K $ is the filter, and $ * $ denotes the convolution operation.
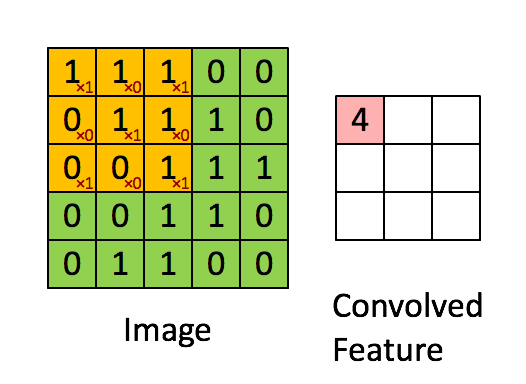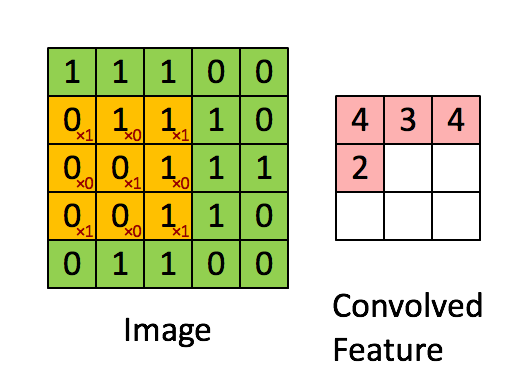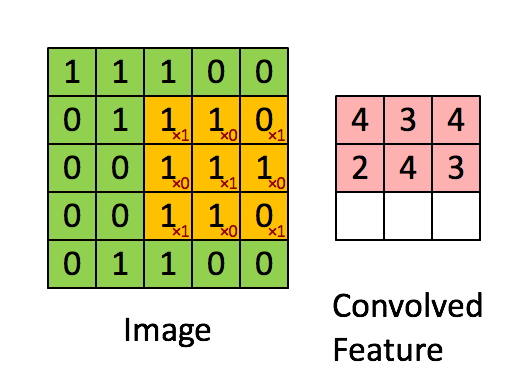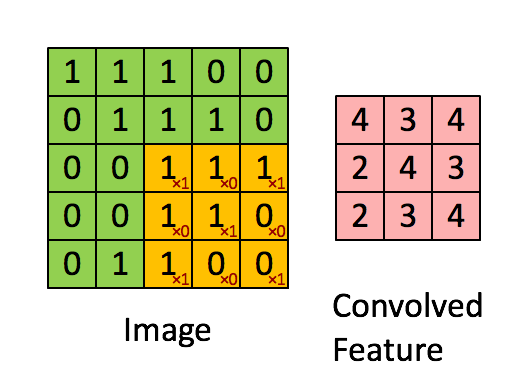
Pooling is a down-sampling operation that reduces the spatial dimensions of the feature map, retaining the most important information and reducing the computational load.
- Max Pooling: Takes the maximum value from a patch of the feature map.
- Average Pooling: Takes the average value from a patch of the feature map.

After several convolutional and pooling layers, the high-level reasoning in the neural network is done via fully connected layers. Neurons in a fully connected layer have full connections to all activations in the previous layer.
The complete CNN architecture combines these components:
- Convolutional Layers: Extract features using filters
- Pooling Layers: Reduce spatial dimensions
- Fully Connected Layers: Perform high-level reasoning
R-CNN is one of the pioneering works in object detection using deep learning. It was introduced by Ross Girshick et al. in 2014.
R-CNN consists of three main components:
- Region Proposal: Generates region proposals using selective search.
- Feature Extraction: Extracts features from each region proposal using a pre-trained CNN.
- Classification and Bounding Box Regression: Classifies each region proposal and refines the bounding box coordinates using SVMs and linear regression.
-
Region Proposal:
- Use selective search to generate around 2000 region proposals per image.
-
Feature Extraction:
- Warp each region proposal to a fixed size (e.g., 224x224 pixels).
- Pass each warped region through a pre-trained CNN (e.g., AlexNet) to extract features.
-
Classification and Bounding Box Regression:
- Use SVMs to classify each region proposal.
- Use linear regression to refine the bounding box coordinates.
- Speed: R-CNN is slow because it processes each region proposal independently, leading to redundant computations.
- Training: The training process is multi-stage and complex, involving separate training for the CNN, SVMs, and bounding box regressors.
- Storage: Requires a large amount of storage to save the features for each region proposal.
Fast R-CNN is an improvement over R-CNN, introduced by Ross Girshick in 2015. It addresses the speed and storage issues of R-CNN.
Fast R-CNN consists of two main components:
- Region Proposal: Generates region proposals using selective search or EdgeBoxes.
- Region of Interest (RoI) Pooling: Projects the region proposals onto the feature map and pools the features.
- Classification and Bounding Box Regression: Classifies each region proposal and refines the bounding box coordinates using a single network.
-
Region Proposal:
- Use selective search or EdgeBoxes to generate region proposals.
-
Feature Extraction:
- Pass the entire image through a pre-trained CNN to extract a feature map.
-
RoI Pooling:
- Project the region proposals onto the feature map.
- Pool the features from each region proposal to a fixed size (e.g., 7x7).
-
Classification and Bounding Box Regression:
- Pass the pooled features through fully connected layers to classify each region proposal and refine the bounding box coordinates.
- Speed: Fast R-CNN is faster because it shares the computation of the feature map for all region proposals.
- Training: The training process is end-to-end, simplifying the training pipeline.
- Storage: Requires less storage because it does not need to save the features for each region proposal.
Faster R-CNN is an improvement over Fast R-CNN, introduced by Shaoqing Ren et al. in 2015. It addresses the bottleneck of region proposal generation.
RPN is a fully convolutional network that predicts region proposals directly from the feature map. It consists of two main components:
- Anchor Boxes: Pre-defined boxes of different sizes and aspect ratios.
- Classification and Bounding Box Regression: Classifies each anchor box as foreground or background and refines the bounding box coordinates.
Faster R-CNN consists of two main components:
- Region Proposal Network (RPN): Generates region proposals from the feature map.
- Fast R-CNN: Classifies each region proposal and refines the bounding box coordinates.
-
Feature Extraction:
- Pass the entire image through a pre-trained CNN to extract a feature map.
-
Region Proposal Network (RPN):
- Slide a small network over the feature map to predict region proposals.
- For each position in the feature map, predict the probability of each anchor box being foreground or background and refine the bounding box coordinates.
-
RoI Pooling:
- Project the region proposals onto the feature map.
- Pool the features from each region proposal to a fixed size (e.g., 7x7).
-
Classification and Bounding Box Regression:
- Pass the pooled features through fully connected layers to classify each region proposal and refine the bounding box coordinates.
- Speed: Faster R-CNN is faster because it generates region proposals directly from the feature map, eliminating the need for external region proposal methods.
- Accuracy: The region proposals generated by RPN are more accurate because they are learned from the data.
Mask R-CNN is an extension of Faster R-CNN for instance segmentation, introduced by Kaiming He et al. in 2017. It adds a branch for predicting segmentation masks on top of the existing branch for bounding box recognition.
Mask R-CNN consists of three main components:
- Region Proposal Network (RPN): Generates region proposals from the feature map.
- RoIAlign: Aligns the region proposals to the feature map.
- Mask Branch: Predicts segmentation masks for each region proposal.
-
Feature Extraction:
- Pass the entire image through a pre-trained CNN to extract a feature map.
-
Region Proposal Network (RPN):
- Slide a small network over the feature map to predict region proposals.
- For each position in the feature map, predict the probability of each anchor box being foreground or background and refine the bounding box coordinates.
-
RoIAlign:
- Project the region proposals onto the feature map.
- Align the region proposals to the feature map using bilinear interpolation to preserve spatial correspondence.
-
Mask Branch:
- Pass the aligned features through a small fully convolutional network to predict segmentation masks for each region proposal.
-
Classification and Bounding Box Regression:
- Pass the aligned features through fully connected layers to classify each region proposal and refine the bounding box coordinates.
The loss function for Mask R-CNN is a multi-task loss that combines the losses for classification, bounding box regression, and mask prediction:
- $ L_{cls} $: Classification loss (cross-entropy loss).
- $ L_{box} $: Bounding box regression loss (smooth L1 loss).
- $ L_{mask} $: Mask prediction loss (binary cross-entropy loss).
RoIAlign is a method for aligning the region proposals to the feature map. It addresses the quantization issue of RoIPool by using bilinear interpolation to compute the exact values of the input features. This preserves the spatial correspondence between the input and output features, leading to more accurate segmentation masks.
Mask R-CNN has been applied to various tasks, including:
- Instance Segmentation: Delineating each object at a pixel level.
- Object Detection: Detecting and locating objects within an image.
- Robot Manipulation: Estimating object position for grasp planning.
Experiments on the COCO dataset have shown that Mask R-CNN outperforms previous state-of-the-art instance segmentation models by a large margin.
- Temporal Information: Mask R-CNN only works on images, so it cannot explore temporal information of objects in a dynamic setting.
- Motion Blur: Mask R-CNN usually suffers from motion blur at low resolution and encounters failures.
- Supervised Training: Mask R-CNN requires labeled data for training, which can be difficult to obtain.
Future work includes:
- Hand Segmentation: Combining Mask R-CNN with tracking for hand segmentation under different viewpoints.
- Embodied Amodal Recognition: Applying Mask R-CNN for agents to learn to move strategically to improve their visual recognition abilities.

Recurrent Neural Networks (RNNs) are a type of neural network designed for processing sequential data, such as time series or natural language. They have loops within their architecture that allow information to persist.
RNNs consist of the following components:
- Input Layer: Receives the input data.
- Hidden Layer: Processes the input data and maintains a hidden state that captures information from previous time steps.
- Output Layer: Produces the final output.
The hidden state at time step $ t $ is given by:
where $ h_t $ is the hidden state at time step $ t $, $ W_h $ and $ W_x $ are the weight matrices, $ x_t $ is the input at time step $ t $, $ b $ is the bias, and $ f $ is the activation function.
- Simple RNN: The basic form of RNN with a single hidden layer.
- LSTM (Long Short-Term Memory): A type of RNN designed to mitigate the vanishing gradient problem and capture long-term dependencies.
- GRU (Gated Recurrent Unit): A simplified version of LSTM with fewer parameters.
- Natural Language Processing: Language modeling, machine translation, text generation.
- Time Series Analysis: Stock price prediction, weather forecasting.
- Speech Recognition: Converting spoken language into text.
Long Short-Term Memory (LSTM) networks are a type of RNN designed to capture long-term dependencies in sequential data. They introduce a memory cell and gates to control the flow of information.
LSTM networks consist of the following components:
- Input Gate: Controls the flow of input activations into the memory cell.
- Forget Gate: Controls the flow of information from the previous time step into the memory cell.
- Output Gate: Controls the flow of information from the memory cell to the output.
- Memory Cell: Stores information over time.
The hidden state at time step $ t $ is given by:
where $ h_t $ is the hidden state at time step $ t $, $ o_t $ is the output gate, $ C_t $ is the memory cell, and $ \odot $ denotes element-wise multiplication.
-
Input Gate:
- Compute the input gate activation: $ i_t = \sigma(W_i [h_{t-1}, x_t] + b_i) $
- Compute the candidate memory cell: $ \tilde{C}t = \tanh(W_C [h{t-1}, x_t] + b_C) $
-
Forget Gate:
- Compute the forget gate activation: $ f_t = \sigma(W_f [h_{t-1}, x_t] + b_f) $
-
Memory Cell:
- Update the memory cell: $ C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t $
-
Output Gate:
- Compute the output gate activation: $ o_t = \sigma(W_o [h_{t-1}, x_t] + b_o) $
- Compute the hidden state: $ h_t = o_t \odot \tanh(C_t) $
- Natural Language Processing: Language modeling, machine translation, text generation.
- Time Series Analysis: Stock price prediction, weather forecasting.
- Speech Recognition: Converting spoken language into text.
Generative Adversarial Networks (GANs) are a type of deep learning model designed for generating new data instances that resemble the training data. They consist of two networks: a generator and a discriminator.
GANs consist of the following components:
- Generator: Generates new data instances.
- Discriminator: Distinguishes between real and generated data instances.
The generator and discriminator are trained simultaneously in a minimax game, where the generator tries to fool the discriminator, and the discriminator tries to correctly classify the data.
-
Generator:
- Generate new data instances: $ G(z) $
- Update the generator weights to maximize the discriminator's error.
-
Discriminator:
- Classify the data instances: $ D(x) $
- Update the discriminator weights to minimize the classification error.
The loss function for GANs is given by:
$$ \min_G \max_D V(D, G) = \mathbb{E}{x \sim p{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] $$
where $ G $ is the generator, $ D $ is the discriminator, $ x $ is the real data, $ z $ is the noise vector, $ p_{data}(x) $ is the data distribution, and $ p_z(z) $ is the noise distribution.
- Image Generation: Generating realistic images.
- Image Super-Resolution: Enhancing the resolution of images.
- Style Transfer: Transferring the style of one image to another.
Deep learning, with its foundations in neural networks, has revolutionized various fields by enabling the modeling of complex patterns in data. Neural networks, from simple perceptrons to complex architectures like CNNs, RNNs, LSTMs, and GANs, have paved the way for advanced models like R-CNN, Fast R-CNN, and Mask R-CNN. These models have significantly improved object detection, instance segmentation, sequential data processing, and data generation, making them invaluable tools in computer vision, natural language processing, and beyond.
This comprehensive understanding of deep learning, from the basics to advanced concepts, should give you a solid foundation in the field. If you have any specific questions or need further clarification on any topic, feel free to ask!
| Activation Function | Formula | Use Case |
|---|---|---|
| Sigmoid | Output layer for binary classification | |
| Tanh | Hidden layers | |
| ReLU | Hidden layers | |
| Leaky ReLU | Hidden layers to mitigate dying ReLU | |
| Softmax | Output layer for multi-class classification |
| Loss Function | Formula | Use Case |
|---|---|---|
| Mean Squared Error (MSE) Loss | Regression problems | |
| Cross-Entropy Loss | Binary classification problems | |
| Categorical Cross-Entropy Loss | Multi-class classification problems | |
| Hinge Loss | Support Vector Machines (SVMs) |
| Optimization Algorithm | Description | Use Case |
|---|---|---|
| Gradient Descent | Updates the weights in the direction of the negative gradient of the loss function | Basic optimization, slow for large datasets |
| Stochastic Gradient Descent (SGD) | Updates the weights using a single training example at a time | Faster than gradient descent, but can be noisy |
| Mini-batch Gradient Descent | Updates the weights using a small batch of training examples | Balances speed and stability |
| Adam | Adaptive learning rate optimization algorithm | Efficient and effective for training deep networks |
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-444.
- He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask R-CNN. IEEE International Conference on Computer Vision (ICCV).
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735-1780.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems.
This document was prepared by Muhammad Abdullah. For more information about deep learning and artificial intelligence, feel free to connect with me on LinkedIn.