This repository presents a production-ready AI inference stack for Kubernetes, designed to run advanced large language models (LLMs) of your choice—including but not limited to Qwen3-32B—on NVIDIA L40S GPUs using vLLM. The stack integrates Ollama for embeddings and image analysis, and provides a unified interface through OpenWebUI with secure Microsoft OAuth2 authentication. All services are orchestrated within Kubernetes and securely exposed via Ingress under an internal DNS hostname (e.g., https://ai.com.tr), enabling scalable, high-performance AI capabilities on your own infrastructure.
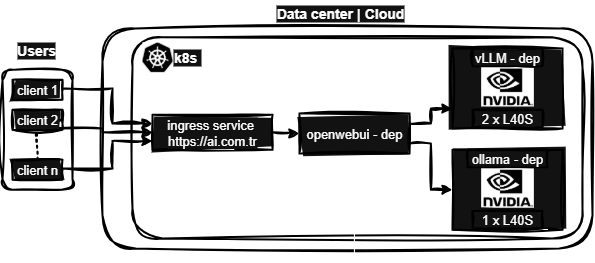
- Kubernetes AI Stack – Flexible and High-Performance LLM Inference
Make sure you meet the following prerequisites before getting started:
- Kubernetes (k8s) is installed and running.
- A node with an NVIDIA GPU (e.g., L40S, A100, H100) is available.
- NVIDIA Container Toolkit is installed.
💡 For detailed instructions on setting up Kubernetes, NVIDIA GPU support, and the NVIDIA Container Toolkit, please refer to:
uzunenes/triton-server-hpa
We will load the qwen3-32B model in parallel across GPUs with IDs 1 and 2. The GPU with ID 0 will be used for other models handling embedding and vision tasks.
Apply the vLLM deployment manifest (k8s/vllm-dep.yaml):
kubectl apply -f k8s/vllm-dep.yaml💡 Note: By setting CUDA_VISIBLE_DEVICES=1,2 and NVIDIA_VISIBLE_DEVICES=1,2, we ensure the application only uses GPUs with IDs 1 and 2. This helps isolate resources and prevents interference with workloads on other GPUs.
Apply the vLLM service manifest (k8s/vllm-svc-np.yaml):
kubectl apply -f k8s/vllm-svc-np.yamlTo verify your vLLM deployment, send a sample completion request using curl.
First, create a prompt JSON file:
cat <<EOF > prompt.json
{
"model": "qwen/qwen3-32B",
"prompt": "Hello AI, tell me something interesting about deep learning.",
"temperature": 0.7,
"max_tokens": 200
}
EOFThen, run the following command (replace <NODE_IP> with your node's IP):
curl http://<NODE_IP>:<NODEPORT>/v1/completions \
-H "Content-Type: application/json" \
-d @prompt.jsonYou should receive a JSON response with the model’s completion, similar to:
{
"id": "cmpl-d3fed9c20601454da49ca7c0479a0371",
"object": "text_completion",
"created": 1754299179,
"model": "qwen/qwen3-32B",
"choices": [
{
"index": 0,
"text": " Okay, so I need to find something interesting about deep learning. Let me start by recalling...",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 11,
"total_tokens": 211,
"completion_tokens": 200,
"prompt_tokens_details": null
},
"kv_transfer_params": null
}💡 Note: The actual response format may vary depending on the deployed model and API configuration.
Apply the ollama deployment manifest (k8s/ollama-dep.yaml):
kubectl apply -f k8s/ollama-dep.yamlApply the Ollama service manifest (k8s/ollama-svc-np.yaml):
kubectl apply -f k8s/ollama-svc-np.yamlAccess the Ollama pod and download the desired model. Example for the nomic-embed-text model:
kubectl exec -it <OLLAMA_POD_NAME> -- /bin/bash
ollama pull all-minilm:latest #embedding
ollama pull qwen2.5vl:7b #visionOnce the model is downloaded, Ollama will be ready to handle requests.
To verify that Ollama is running and available, you can query the API for the list of downloaded models:
curl http://<NODE_IP>:<NODEPORT>/api/tagsYou should receive a JSON response listing all available models.
{
"models": [
{
"name": "all-minilm:latest",
"model": "all-minilm:latest",
"modified_at": "2025-07-29T09:31:19.089668004Z",
"size": 45960996,
"digest": "1b226e2802dbb772b5fc32a58f103ca1804ef7501331012de126ab22f67475ef",
"details": {
"parent_model": "",
"format": "gguf",
"family": "bert",
"families": [
"bert"
],
"parameter_size": "23M",
"quantization_level": "F16"
}
},
{
"name": "qwen2.5vl:7b",
"model": "qwen2.5vl:7b",
"modified_at": "2025-07-28T07:54:54.216774452Z",
"size": 5969245856,
"digest": "5ced39dfa4bac325dc183dd1e4febaa1c46b3ea28bce48896c8e69c1e79611cc",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen25vl",
"families": [
"qwen25vl"
],
"parameter_size": "8.3B",
"quantization_level": "Q4_K_M"
}
}
]
}💡 Note: Replace <NODE_IP> with your Kubernetes worker node’s IP address, Replace with the actual NodePort value from your service manifest. 💡 Note: You can add embedding and vision task models directly from the openwebui user interface.
You can view the models loaded on the GPU by running the nvidia-smi command inside the pod.

Apply the OpenWebUI deployment manifest (k8s/openwebui-dep.yaml):
kubectl apply -f k8s/openwebui-dep.yamlkubectl apply -f k8s/openwebui-svc.yaml
kubectl apply -f k8s/openwebui-svc-ingress.yamlTo enable Microsoft OAuth2 authentication in OpenWebUI, follow these steps:
-
Create an Azure AD Application
- Go to Azure Portal.
- Navigate to Azure Active Directory → App registrations → New registration.
- Give your application a name (e.g.,
OpenWebUI). - In the Redirect URI field, add the following:
https://ai.com.tr/oauth2/callback - Click Register.
-
Obtain Client ID and Tenant ID
- After registration, go to your application page.
- Note down the Application (client) ID and Directory (tenant) ID.
-
Create a Client Secret
- Go to the Certificates & secrets section.
- Create a new secret using New client secret.
- Save the generated value (it will only be shown once).
-
Configure OpenWebUI
- In your Kubernetes environment, update the OpenWebUI deployment manifest with the following environment variables:
env:
- name: ENABLE_OAUTH_SIGNUP
value: "true"
- name: OAUTH2_PROVIDER
value: microsoft
- name: OAUTH2_CLIENT_ID
value: "<MICROSOFT_CLIENT_ID>"
- name: OAUTH2_CLIENT_SECRET
value: "<MICROSOFT_CLIENT_SECRET>"
- name: OAUTH2_REDIRECT_URI
value: "https://ai.com.tr/oauth2/callback"
- name: MICROSOFT_CLIENT_TENANT_ID
value: "<MICROSOFT_CLIENT_TENANT_ID>"
- name: OPENID_PROVIDER_URL
value: "https://login.microsoftonline.com/<MICROSOFT_CLIENT_TENANT_ID>/v2.0/.well-known/openid-configuration"
- name: OAUTH_MERGE_ACCOUNTS_BY_EMAIL
value: "true"
go run load-test.govLLM Load Test Results
| Metric | Value |
|--------|-------|
| Total Requests | 20 |
| Total Tokens | 10773 |
| Total Time (s) | 135.46 |
| Tokens per Second | 79.53 |
I would like to thank my teammates for their valuable support during this work.
- Alper Aldemir
- Ceyhun Erdil
- Güneş Balçık
- Mehmet Ali Erol
- Zekeriye Altunkaynak